
MongoDB Index #.1 Architecture

MongoDB Index #.1
Index 란?
DBMS에서 인덱스란 컬럼과 레코드가 저장된 위치를 key-value로 관리되어지는 검색 속도를 향상시키기 위한 자료구조 입니다. 프로그래밍 언어를 공부하다 보면 SortedList와 ArrayList라는 자료구조를 접하게 되는데, DBMS의 인덱스는 SortedList와 동일한 자료 구조이며 데이터 파일은 ArrayList와 동일한 자료 구조를 갖습니다. SortedList는 저장된 값들을 순서대로 정렬된 상태로 유지하는 자료구조이며, ArrayList는 데이터를 저장하는 순서대로 유지하는 구조입니다.
인덱스는 새로운 데이터가 기록될 때마다 새로운 순서로 정렬 작업을 하기 때문에 쓰기 작업이 느리지만, 이미 정렬된 구조를 가지고 있기 때문에 데이터를 찾아 읽어오는 작업에서는 매우 빠르게 동작을 합니다. MongoDB에서는 find() 작업시 인덱스의 여부에 따라 속도가 달라지게 됩니다. 쓰기 작업이 빈번한 데이터베이스, 혹은 컬렉션이 있다면 인덱스를 다수 추가하는 것은 쓰기 작업의 속도를 저하 할 수도 있지만, 인덱스를 추가함으로써 읽기 속도를 어느정도 보장할 수 있기 때문에 쓰기보다 읽기 작업이 주로 발생하는 데이터베이스나 컬렉션이라면 인덱스를 생성하여 성능을 높일수 있습니다.
단, 인덱스 생성이 절대적으로 데이터베이스의 성능을 높여주는 것은 아니며, FIND 사용되어지는 필드 값이나 배열이라고 해서 무조건 인덱스를 생성해서는 안되며, 인덱스가 없이도 충분히 연산 속도가 보장된다면 굳이 인덱스를 생성하지 않아도 괜찮으며, 사용되지 않는 인덱스를 많이 생성하는 것도 자원의 낭비로 이어질 수 있습니다.
MongoDB의 인덱스
우선 MongoDB는 4.4버전인 현재에도 다른 RDBMS들과는 다르게 Clustered Index를 지원하지 않습니다. Clustered Index의 장점중의 하나인 랜덤 엑세스 없이 레코드를 읽는 기능은 빠른 레인지 스캔 속도를 자랑합니다. 하지만 MongoDB는 아직까지 지원하고 있지 않은 기능입니다.
MongoDB의 기본 인덱스 구조는 B-Tree 인덱스입니다. Clustered Index가 아니기 때문에 프라이머리 인덱스와 세컨더리 인덱스 간의 내부구조가 동일하며, 최상단의 루트 노드, 중간 위치의 브랜치 노드, 그리고 최하단의 리프 노드로 구성되어 있습니다.
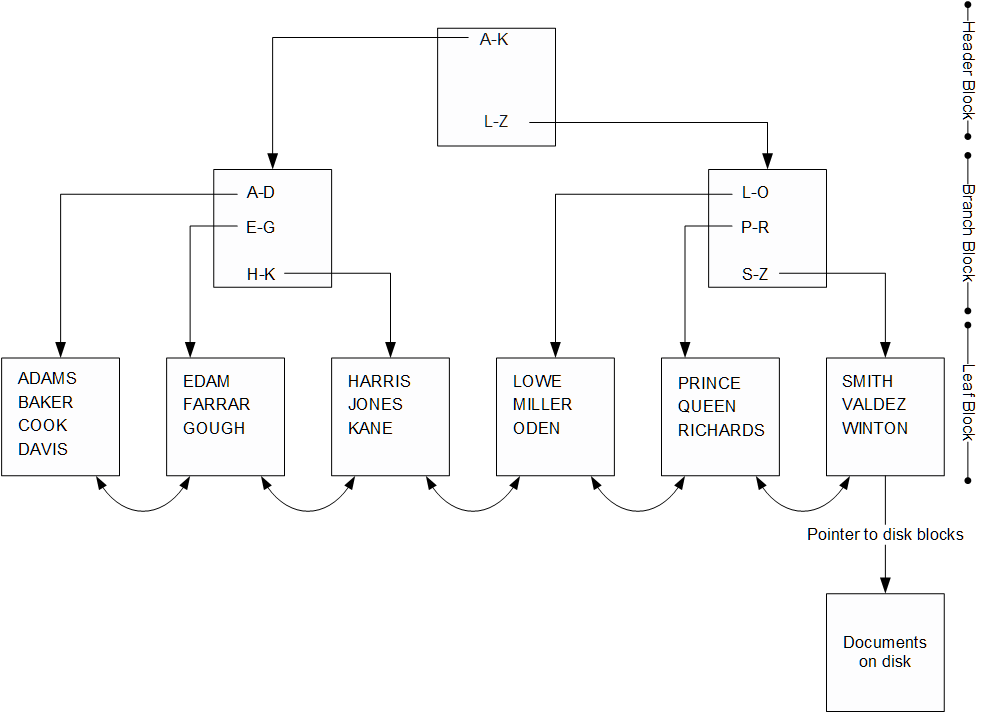
B-tree 인덱스 구조가 다른 인덱스의 구조에 비해 다음과 같은 장점이 있습니다.
- 각 리프 노드가 동일한 깊이에 있기 때문에 균등한 응답 속도를 보장합니다. 하나의 컬렉션 내에서 모든 도큐먼트가 3~4개의 I/O 이상으로 떨어져 있지 않습니다.
- B-Tree는 깊이가 최대 4개 (헤더 블록 1개, 브랜치 블록 2개, 리프 블록 1개)이므로 대규모 컬렉션에 대해 우수한 성능을 제공합니다. 일반적으로 문서를 찾는데 4개 이상의 I/O가 필요하지 않습니다. 실제로 헤더 블록은 거의 항상 미리 메모리에 로드되고, 브랜치 블록들도 일반적으로 메모리에 로드되기 때문에 실제 디스크 읽기 수는 일반적으로 1~2개에 불과합니다.
- B-Tree 인덱스는 정확하고 빠른 조회뿐만 아니라 레인지 스캔 쿼리를 지원합니다. 이 것이 가능한 이유는 이전 리프 블록과 다음 리프 블록에 대한 링크 때문입니다.
각각의 노드들은 노드하나에 한개의 데이터가 아닌 복수의 데이터를 저장하는 버켓(bucket)이라는 저장소를 이용합니다. 그렇기 때문에 하나의 노드에 많은 데이터를 담을수 있으며, 트리의 깊이를 낮추고 Cache Hit rate를 높일 수 있습니다. 버켓안에 포함된 데이터는 B-Tree 구조는 아니며, 따라서 버켓안의 데이터를 검색할 때는 순차 루프를 필요로 하게 됩니다.

MongoDB의 버켓 구조를 보여주는 그림입니다. 2010년 4월 이전의 인덱스 구조는 Version 0으로, 이후의 인덱스 구조는 Version 1구조를 사용합니다. 두 개의 버전이 공존하는 이유는 2010년 4월 이전에 사용되던 데이터 파일에 대한 호환성을 위해서 입니다. Version 0에서는 B-Tree 노드의 헤더 영역과 인덱스의 데이터를 저장하기 위해 BSON 객체를 직접 사용하였지만, Version 1에서는 인덱스 데이터를 직접 저장하는 방법으로 바꿔 메모리 효율성을 증가시켰습니다.
MongoDB의 인덱스는 다른 NoSQL과 달리 RDBMS와 같은 세컨더리 인덱스를 지원하며, 복합 인덱스와 같은 유연한 특성을 가지고 있습니다. 하지만 MongoDB의 인덱스는 버켓에 키 값을 저장하기 때문에, 도큐먼트에 저장된 데이터와 중복 저장되는 단점이 있고, 인덱스를 위한 입출력 기술이 운영체제가 제공하는 Page Fault 방식을 같이 사용하기 때문에 메모리가 부족한 시스템에서는 오히려 검색 속도가 저하되는 단점이 있습니다. 적은 메모리를 사용할 경우 인덱스를 사용하지 않는 편이 검색 시간을 단축하기도 합니다.
또, MongoDB는 Schema-Free 데이터베이스라고 말합니다. 이것은 컬렉션에 대해서는 맞는 이야기지만, 인덱스에서는 맞지 않는 이야기입니다. 인덱스는 내부적으로 별도의 스키마를 가지고 있으며, 각 인덱스들이 어떤 인덱스인지, 인덱스를 구성하는 필드는 어떤것인지에 대한 메타정보를 가지고 있습니다.
WiredTiger 스토리지 엔진의 인덱스
WiredTiger 스토리지 엔진은 인덱스 키 엔트리에 도큐먼트마다 고유의 식별자를 할당하며 Record-Id로 부여합니다. 이때 도큐먼트의 고유 식별자는 Auto-Increment 방식을 사용합니다. Record-Id는 64bit의 int(정수 타입)을 사용하며 컬렉션 단위로 별도의 자동 증가값을 사용합니다. WiredTiger 스토리지 엔진의 Record-Id는 나중에 도큐먼트의 크기가 증가하여도 크게 부하가 없고, 데이터 파일내에서 위치가 이동하더라도 처음 할당된 논리적인 주소 값은 변하지 않고 계속 유지됩니다.
WiredTiger 스토리지 엔진은 내부적으로 Record-Id 값을 인덱스 키로 가지는 내부 인덱스가 존재합니다. WiredTiger의 내부 인덱스는 Clustered Index 인덱스로 구조를 가지고 있고, 이 인덱스는 사용자가 임의적으로 변경하거나 사용할 수 있는 인덱스는 아닙니다. 위에도 설명했듯이 사용자가 생성한 인덱스는 clustered Index를 사용할 수 없습니다.
이러한 WiredTiger 스토리지 엔진의 특성 때문에 사용자 인덱스를 통해 검색을 할때도, WiredTiger 내부 인덱스를 이용해 Record-Id 값을 조회하기 때문에 도큐먼트를 검색할 때 두 번의 인덱스 검색을 수행해야 최종 결과를 얻을 수 있습니다. 이런 특성 덕분에 데이터 검색에서 속도에 대해 손해보는 점이 있지만, 데이터 변경은 유연하게 처리된다는 장점이 있습니다.
Local Index
MongoDB가 다른 NoSQL과는 다르게 아주 다양한 형태의 세컨더리 인덱스들을 지원합니다. 이러한 MongoDB의 특성 때문에 OLTP 서비스 환경에서도 RDBMS에 밀리지 않습니다. MongoDB의 세컨더리 인덱스는 Local 인덱스로 관리 되는데, 각 샤드별로 자신이 저장하고 있는 도큐먼트에 대해서만 해당 샤드가 인덱스를 관리합니다. 따라서 프라미어리 인덱스나 유니크 인덱스는 샤드 키를 반드시 포함해야 하거나 응용 프로그램 수준에서 유니크함을 보장해야 합니다.
샤드간의 데이터를 균등하게 배치하기 위해 MongoDB는 밸런서(Balancer)가 백그라운드에서 샤드간의 데이터를 균등 분배합니다. 이때 인덱스가 많은 컬렉션은 데이터 밸런싱을 지연시키고 부하를 일으킬 수 있습니다.
MongoDB의 인덱스를 사용할 때 고려해야 하는 점
- 인덱스를 메모리에 적재할 수 있을 정도로 메모리의 크기가 충분한가?
- 인덱스를 설정한 데이터만으로 질의가 가능한가?
연산이 필요없이 하나의 도큐먼트에서 데이터를 모두 가져온다면, MongoDB는 불필요한 도큐먼트를 읽어오지 않으며, 검색과 결과의 출력이 동시에 이루어지므로 빠른 검색이 가능합니다. 반면에 인덱스 필드를 검색하면서 인덱스가 없는 다른 도큐먼트나, 다른 필드를 같이 조회 해야한다면, 각각의 데이터들이 매번 메모리에 로드 되어지므로 많은 메모리 엑세스가 발생한다는 것을 유의해야 합니다.
다음 포스팅
참고 자료
도서 : 맛있는 몽고DB
도서: Real MongoDB
도서: 오픈소스 몽고DB
도서: MongoDB in Action
MongoDB Manual: https://docs.mongodb.com/manual/
http://mongodb.citsoft.net/?p=663
https://dzone.com/articles/effective-mongodb-indexing-part-1
1 Response
[…] 이전 포스팅에서 MongoDB의 기본 인덱스는 B-Tree 인덱스로 되어 있다고 설명했습니다. B-Tree 인덱스는 MongoDB 뿐만 아니라 다양한 RDBMS들에서도 채택하고 있을 만큼 인덱싱 알고리즘 중에서 가장 일반적이고 오래된 알고리즘 입니다. 물론 DBMS의 종류에 따라 조금식 차이가 있지만, 전체적인 틀은 동일합니다. […]