
AWS RDS Aurora V1 to V2 업그레이드 회고

특명! 메인 DB를 업그레이드 하라!
정말 오랜만에 글이네요. EOL 준비를 하느라 조금 정신이 없었습니다.
MySQL 5.6은 이미 일찌감치 EOL 되어 더 이상 패치도, 기술 지원도 되지 않는 상황이었습니다. MySQL 5.6이 베이스였던 Aurora v1은 MySQL 5.6이 EOL된 시점에서 2년이나 더 서비스를 유지 했으나, 결국 2023년 2월 28일로 MySQL 5.6을 역사속으로 보내기로 결정합니다. 현재 재직중인 회사의 메인 데이터베이스가 아직까지 Aurora V1 1.22.2 였기에 두려움 반 기대 반으로 업그레이드 작업을 진행 할 수 밖에 없었습니다.
붉은 색 경고등이 삐용삐용 들어옵니다.
업그레이드 전략
RDS Aurora v1의 서비스를 종료에 맞춰 업그레이드를 지원하기 위해 AWS는 블루/그린 업그레이드 배포 시스템을 제공하였으나, Aurora의 기본 설정이 OFF인 binlog를 켜야한다는 것은 사전에 메인 DB를 재부팅 해야하는 작업을 선행해야 했고, 1.22.2 버전은 바로 v3 버전으로 업그레이드 할 수 없는 버전이기 때문에, 1.22.3 이상으로 업그레이드를 하고 다시 2.11.1 버전으로 올려야하는 번거로움이 있습니다. 스냅샷을 이용한 복원을 하게 되면 바로 2.11.1 버전으로 바로 복원이 가능하고 블루/그린 배포후에 기존 DB의 엔드포인트가 바뀌는 문제 때문에, 원본 DB를 건드리지 않고 서비스 점검 시간을 공지하고 종료한 채 업그레이드를 진행하는 것으로 방향을 잡았습니다.
router53을 통해 DB엔드포인트를 모두 도메인화 했으며, 소스에서는 DB엔드포인트가 바뀌어도 별도의 작업이 필요 없었으며, Rollback을 위해서 기존 DB의 엔드포인트만 다시 router53으로 연결하면 되는 전략을 취했습니다.
실패는 성공의 어머니
1차 작업을 새벽 3시부터 시작하여, 복원 작업을 했는데, 여기서 첫번째 실수가 발생했습니다. 스냅샷을 통해 복원을 하다가 서브넷 그룹을 잘못 설정하여 클러스터를 생성했고, 바로 잘못 생성을 했다는 것을 깨닫고 서브넷 그룹을 다시 붙여 또 한대의 클러스터를 복원했습니다.
2.7TB의 데이터베이스가 복원하는데 걸리는 시간은 테스트 당시 약 40분 전후의 시간이 필요했으나, 하나의 스냅샷에서 두 대의 인스턴스 복원은 인스턴스 복원에 2배 이상의 시간이 소요되었습니다. 인스턴스 생성에 예상보다 더 많은 시간이 소요되자 모두 초조함에 쫓기기 시작했고, 리더 인스턴스를 추가하고, 서비스 중엔 할 수 없었던 몇몇 DB작업을 진행한 후에, 예정된 서비스 오픈 시간이 얼마 남지 않은 상황에서 DB의 최종 복원이 완료 되었습니다.
부랴부랴 서비스를 오픈했더니, 서비스 오픈에 맞춰 세션이 들어오면서 사전에 캐싱이 필요했던 쿼리들이 DB에서 지연되기 시작했고, 쿼리들의 지연이 쌓이기 시작하면서, 커넥션 증가와 헤비 쿼리들이 쌓이기 시작하면서 DB가 OOM되어 재부팅해버리는 현상까지 발생했습니다. 8xlarge라고 너무 방심 했던것도 있고, Client 메모리 부분을 너무 크게 잡아둔 것도 문제 였습니다. 기존 DB는 이미 캐싱이 완료된 상태에서 클라이언트 메모리 값을 크게 조정 했었기 때문에 기존 메모리 값을 그대로 가져왔던게 문제가 될 거라고는 생각을 할 수가 없었습니다.
결국 기존 DB로 롤백을 결정했고, 다시 작업 날짜를 잡기로 했습니다.
서비스 오픈에 대한 실패 원인 분석
첫 번째, 업그레이드를 준비하는 데 있어 준비 과정이 너무 안일했던 것 같았습니다. 시큐리티 그룹, DB인스턴스명, 등등 정해 놓고 진행한 것이긴 하지만, 서브넷 그룹처럼 생성 후 바꾸지 못하는 것들을 제대로 챙기지 못했던 것이 나비 효과가 되어, 하나의 스냅샷으로 두 개의 DB복원 사태를 만들었고, 하나의 스냅샷에서 두 개의 클러스터로 복원 되는 것이 스냅샷으로부터 발생한 I/O 대역 절반으로 나눠지고, 6개의 쿼럼을 위한 스토리지 영역도 두 배로 들어간다는 것을 간과했던 것이죠. RDS Aurora의 스냅샷을 복원하는 과정에서 가장 오래 걸리는 것 중 하나가 AZ에서 스토리지 영역을 확보하는 것인데, 여러 대를 복원하면서 스토리지 영역이 뻥튀기 되어 버린 것도 복원 지연을 만든 큰 이유 중 하나 였습니다.
두 번째, 옵티마이저 변경과 Hash Join과 Parallel 쿼리에 대한 충분한 검증 없이 파라미터를 적용하여 기존 쿼리들이 인덱스를 타지 못하고, 전혀 다른 플랜으로 실행 함에 따라 기본 서비스 쿼리들이 대량의 악성 쿼리로 전환 되었으며 평소 group by, order by 등의 Sort 작업이 많아 다소 크게 설정 해두었던 클라이언트 메모리 설정으로 인해 oom으로 인한 DB 재구동 반복이라는 최악의 사태가 발생하게 되었습니다. 거기에 버퍼에 데이터를 가져와 자주 쓰는 쿼리들의 사전 캐싱을 하는 절차의 부재로 초기 캐싱에 오래걸리는 쿼리들이 무서운 속도로 쌓이기 시작했습니다.
2차 시도는 정말 마지막이라는 각오로!
1차 업그레이드 과정에 놓친 부분을 정리 해봤습니다.
- 작업 절차서의 세밀함
- 파라미터의 꼼꼼한 검수
- 사전에 캐싱에 필요한 쿼리들의 수집
- MySQL 5.7에 맞는 기존 쿼리 튜닝
잔잔바리한 실수를 줄이기 위해 주니어 시절을 떠올리며 그때 그 마음으로 작업 절차서에 모든걸 기록했습니다. 그리고 작업 시간을 앞당겨서 서비스가 몰릴 시간보다 앞서 오픈하여 사전에 QA및 캐싱을 준비하기로 했습니다.
1차 작업 및 평소 서비스 되는 쿼리들을 클라우드 와치의 성능 인사이트에서 찾아 동일 데이터 규모의 MySQL 5.7 버전의 테스트 인스턴스를 구성하여 미친듯이 튜닝했습니다.
파라미터들을 재점검하여 클라이언트 메모리를 조정하고, 기존 운영 환경과 비슷하게 구성하는 것으로 가닥을 잡았습니다. 유일한 변경점은 인덱스 생성 작업을 위해 innoDB_sort_buffer_size를 늘린 것과 쿼리 캐싱을 OFF로 전환하는 것 두 가지만 새롭게 적용했습니다.
서비스 오픈 전 Locust를 이용해 충분한 API를 통한 부하 테스트(물론 사용자 패턴과는 동일하지 않지만)와 서비스에 필요한 헤비 쿼리들의 사전 캐싱 작업을 미리미리 진행 해두었습니다.
모니터링의 중요함
MySQL의 프로세스 리스트를 조회하는 것은 지속적으로 information_schema에 쿼리를 날려 확인해야 합니다. 이 부분을 그라파나에 모니터링를 자동으로 구성하여 실시간으로 미처 잡지 못한 Slowquery에 대한 즉시 대응이 가능할 수 있었습니다. 그라파나에서는 5s가 가장 짧은 오토 리프레쉬 주기 였습니다.
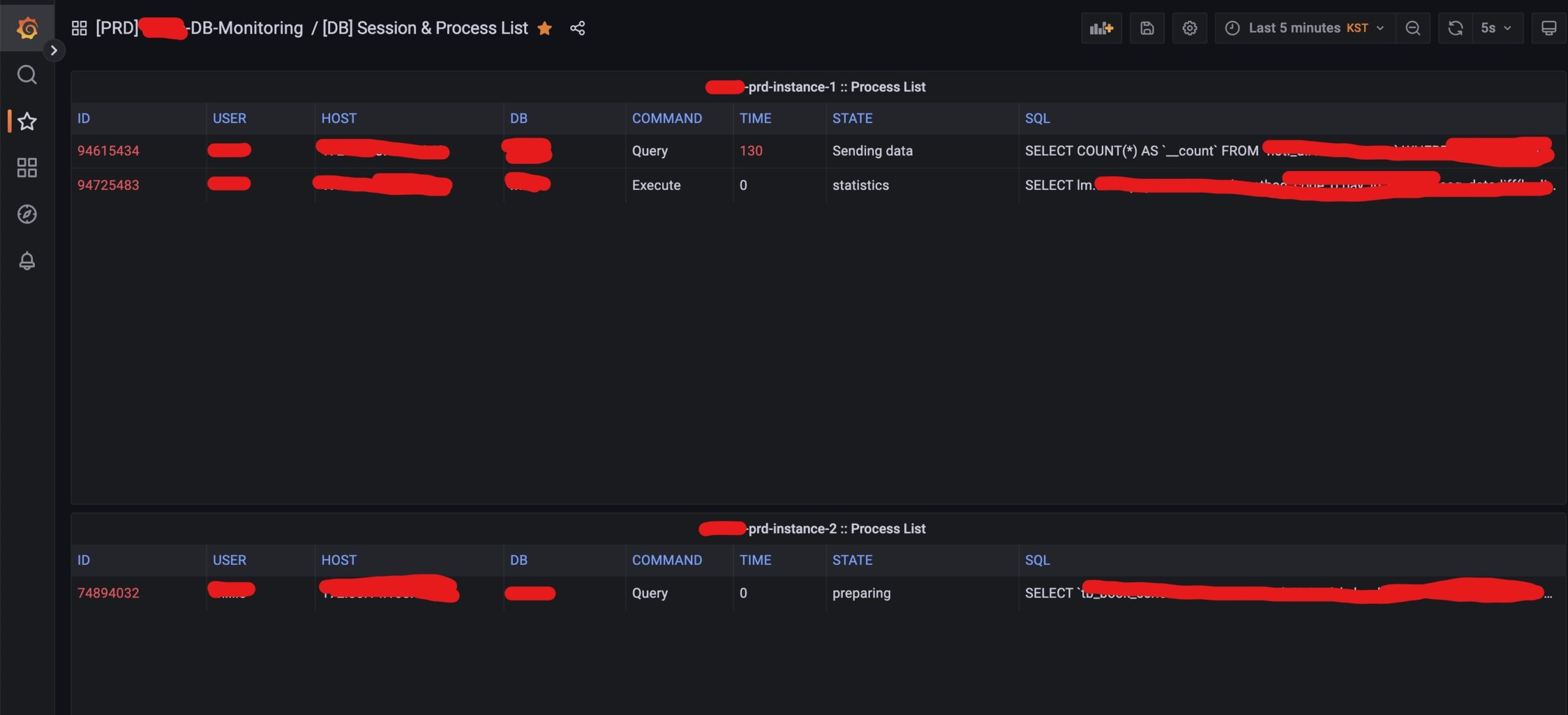
실제 SQL은 DBeaver의 세션 매니저를 통해 수집할 수 있었고, 바로 플랜을 뽑고 수정하여 개발팀으로 전달하였습니다. 서비스 오픈 후에도 혹시나 싶은 장애 상황을 처리하기 위해 밤샘 후 피곤한 몸을 이끌고 좀비모드로 모니터링에 들어갔습니다. 실제로 기존 배치로 돌던 쿼리가 회원 서비스에 장애를 유발하였기 때문에 배치를 차단하고 전체적인 배치 쿼리에 대한 점검을 진행 할 수 있었습니다.
이제는 말할 수 있다. Aurora v2로 업그레이드 시 주의할 것들
이제 Aurora v1의 지원이 종료가 되면서 MySQL 5.6의 수명은 완전히 끝난것 같습니다. 아직도 Aurora v1 버전을 사용하고 있다면 반드시 업그레이드를 진행해야 하며, 다음과 같은 변경 사항을 반드시 점검하고 지나가야 합니다.
MySQL 5.6의 옵티마이저는 RBO, 하지만 MySQL 5.7버전의 옵티마이저는 CBO 입니다. 그렇기 때문에 반드시 미리 5.7 버전의 테스트 버전을 올려 서비스하고 있는 모든 쿼리에 대한 점검을 진행해야 합니다. 기존에 잘 타던 인덱스를 안타는 일도 발생하기도 하며, 플랜이 변하여 쿼리의 속도가 느리지는 현상이 발생할 수 있습니다. 미리미리 슬로우 쿼리를 잡고, 인덱스 생성을 해두고, 배치 및 프로시저, 함수, 트리거들의 루틴들을 점검 해야합니다.
Aurora 업그레이드시 파라미터 적용을 위해서는 재부팅 과정이 반드시 필요합니다. 스냅샷 복원이 아닌, 기존 인스턴스의 수정에 들어가 메이저 버전을 변경하게 되면, 파라미터값을 적용하기 위해 반드시 재부팅이 필요합니다. 이부분 AWS 서포트 엔지니어에게 확인한 부분입니다.
또 버전 업그레이드 시 Table Analyze 작업을 해주는 것이 권장사항입니다. 기존의 SQL 플랜이 변경되는 이유 중 하나가 될 수 있습니다.
서비스 오픈전 쿼리들의 캐싱여부도 중요합니다. 특히나 카운트 쿼리가 많은 경우 좀만 데이터가 무거워져도 첫 SQL 쿼리 실행이 매우 느릴 수 있습니다. DB의 구조가 대부분 처음 SQL을 실행하면 디스크에서 메모리로 데이터를 올리는 작업을 하는데, 서비스가 오픈하면서 유저가 몰리면 지연이 발생할 수 있기 때문에 사전에 QA와 자주 쓰는 무거운 쿼리들의 워밍 작업이 필요합니다.
블루/그린 배포도 좋지만, Binlog를 사용하는 과정에 있어 결국 재부팅하는 과정이 필요하고, 기존 DB의 엔드포인트 변경이 일어나기 때문에 사전에 DB 도메인을 구성해 서비스 하지 않았다면, 블루/그린은 오히려 더 손이 많이 갈 수 있습니다. 또한 블루/그린을 배포하고 나면 과거형이 된 블루를 기존의 엔드포인트 및 설정으로 자동 복원 방법을 지원하지 않습니다. 따라서 충분한 사전 테스트를 거쳐서 결정하시기 바랍니다.
사용하던 배치들 무조건 점검 하고 가세요. 실제 서비스 중 배치가 장시간 돌아 회원 서비스에 일시적으로 Row lock이 발생하기도 했습니다.
업그레이드 성공 및 서비스 정상화
운영과 동일한 환경의 테스트 환경이나 스테이징이 없는 상황이었기 때문에 많은 어려움이 있었으나 결국 부족한 부분들을 잘 보완해서 메인 DB의 업그레이드 작업을 완료할 수 있었습니다. 이번 작업은 정말 오랜만에 큰 작업을 하게 되었기에 1차때 많이 놓친 부분이 있던거 같습니다. SI 엔지니어 시절엔 거의 매주 작업이 있었지만 서비스를 운영하다 보면 큰 작업을 하는 일은 거의 없다보니 참으로 오랜만에 긴장감에서 작업을 진행 했던 것 같습니다. 그런데 내년 10월 Aurora v2 버전도 EOL되는 거 실화입니다. 이제 새로 구축하거나 설치할 계획이 있다면 Aurora v3버전 쓰세요…
최신 댓글