
AWS Aurora의 커스텀 엔드포인트를 활용한 효율적인 데이터베이스 운영 가이드

AWS Aurora의 커스텀 엔드포인트를 이용한 SQL Proxy 없이 내부 조회용 인스턴스와 서비스 읽기 인스턴스 그룹 나누기
AWS Aurora는 엔터프라이즈급 관계형 데이터베이스로서, 고가용성과 뛰어난 성능을 제공합니다. 이번 포스팅에서는 Aurora의 강력한 기능 중 하나인 커스텀 엔드포인트를 활용하여 데이터베이스 워크로드를 효율적으로 분리하고 최적화하는 방법을 상세히 알아보겠습니다.
1. 커스텀 엔드포인트란?
커스텀 엔드포인트는 AWS Aurora 클러스터 내의 특정 데이터베이스 인스턴스 그룹에 대한 접근을 단일 엔드포인트를 통해 관리할 수 있게 해주는 기능입니다.
1.1. 주요 특징
- 클러스터당 최대 5개의 커스텀 엔드포인트 생성 가능
- 정적(Static) 또는 동적(Dynamic) 멤버십 관리 지원
- DNS 전파 시간 약 30초
- 엔드포인트당 최대 초당 1,000개의 연결 처리
- Round-robin 방식의 자동 로드 밸런싱 제공
1.2. 작동 원리
- 지정된 인스턴스 그룹 내에서 자동 부하 분산
- 인스턴스 장애 시 자동 페일오버
- 읽기 전용 트래픽에 대한 지능적 라우팅
2. 내부 조회용 인스턴스와 서비스 읽기 인스턴스 그룹 설정
2.1. 인스턴스 생성
먼저, Aurora 클러스터 내에 다음과 같은 목적의 인스턴스들을 생성합니다:
내부 조회용 인스턴스 (devops-aurora-test-instance-3)
- 데이터 분석 및 내부 보고서 생성용
- 대용량 배치 처리
- BI 도구 연동
- ETL 작업 처리
서비스 읽기 인스턴스 (devops-aurora-test-instance-1, devops-aurora-test-instance-2)
- 실시간 사용자 요청 처리
- API 서비스 지원
- 빠른 응답이 필요한 조회 작업
인스턴스 타입 권장사항
- 분석용 인스턴스: 메모리 최적화 인스턴스
- 서비스용 인스턴스: 범용 인스턴스
여기에서는 동일한 사양으로 3번을 내부 조회용(ETL 및 분석 등), 1,2 번을 서비스로 구성했습니다.
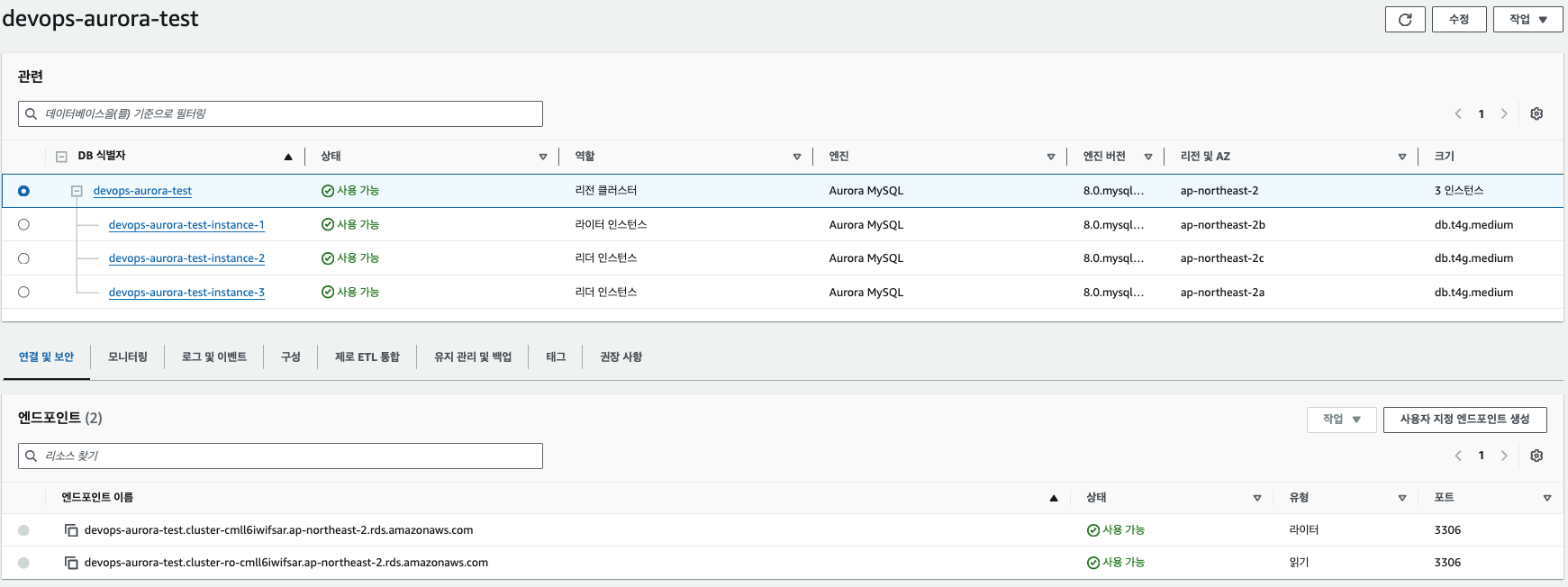
2.2. AWS Aurora 커스텀 엔드포인트 생성 가이드
콘솔을 이용한 생성 방법
1. AWS Management Console에서 Aurora 클러스터 선택
2. Endpoints 탭으로 이동
3. Create Custom Endpoint 버튼 클릭
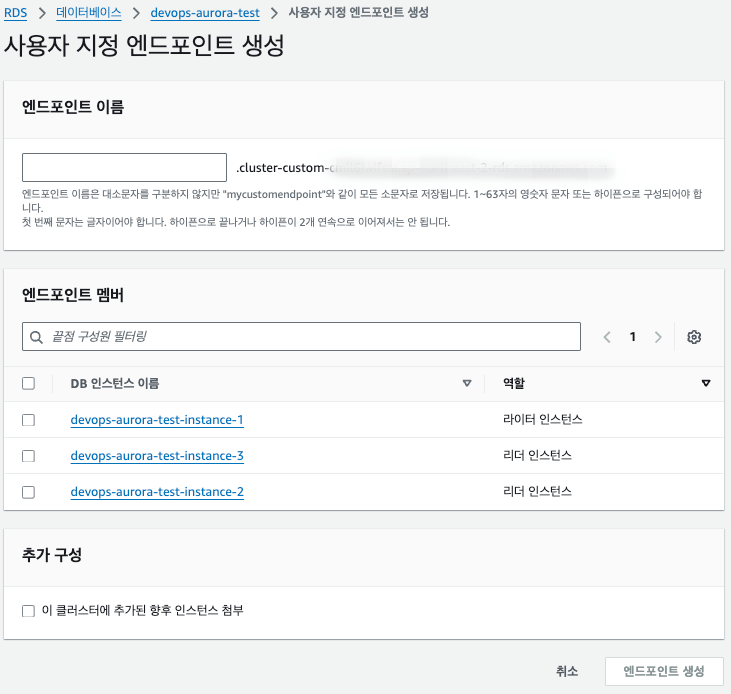
4. 서비스 읽기용 커스텀 엔드포인트 설정
- 엔드포인트 이름 지정
- 서비스 읽기 인스턴스 선택
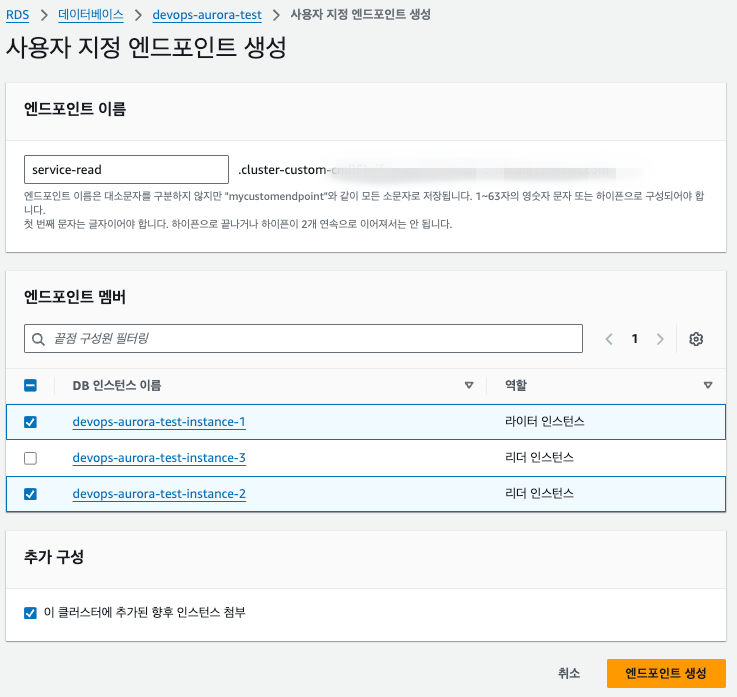
5. 내부 조회용 커스텀 엔드포인트 설정
- 엔드포인트 이름 지정
- 내부 조회용 인스턴스 선택
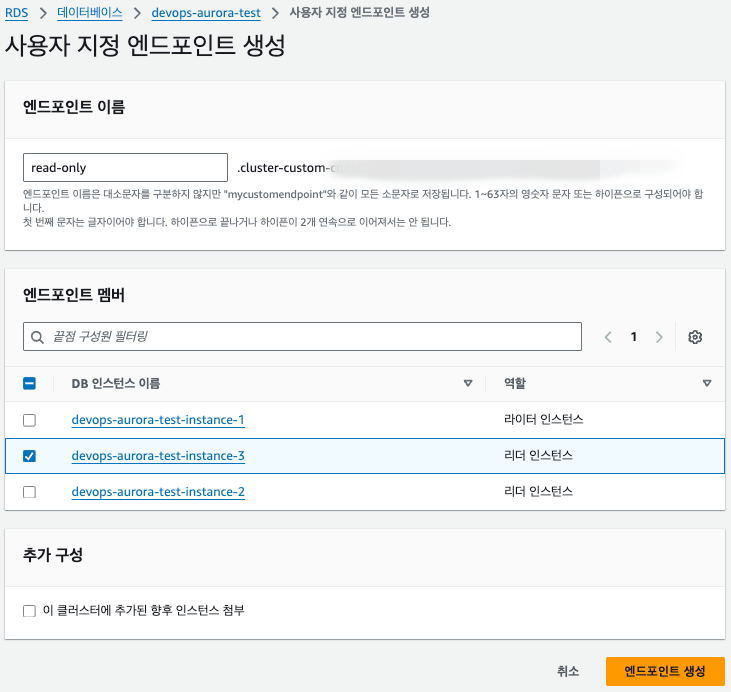
6. 생성된 커스텀 엔드포인트 확인
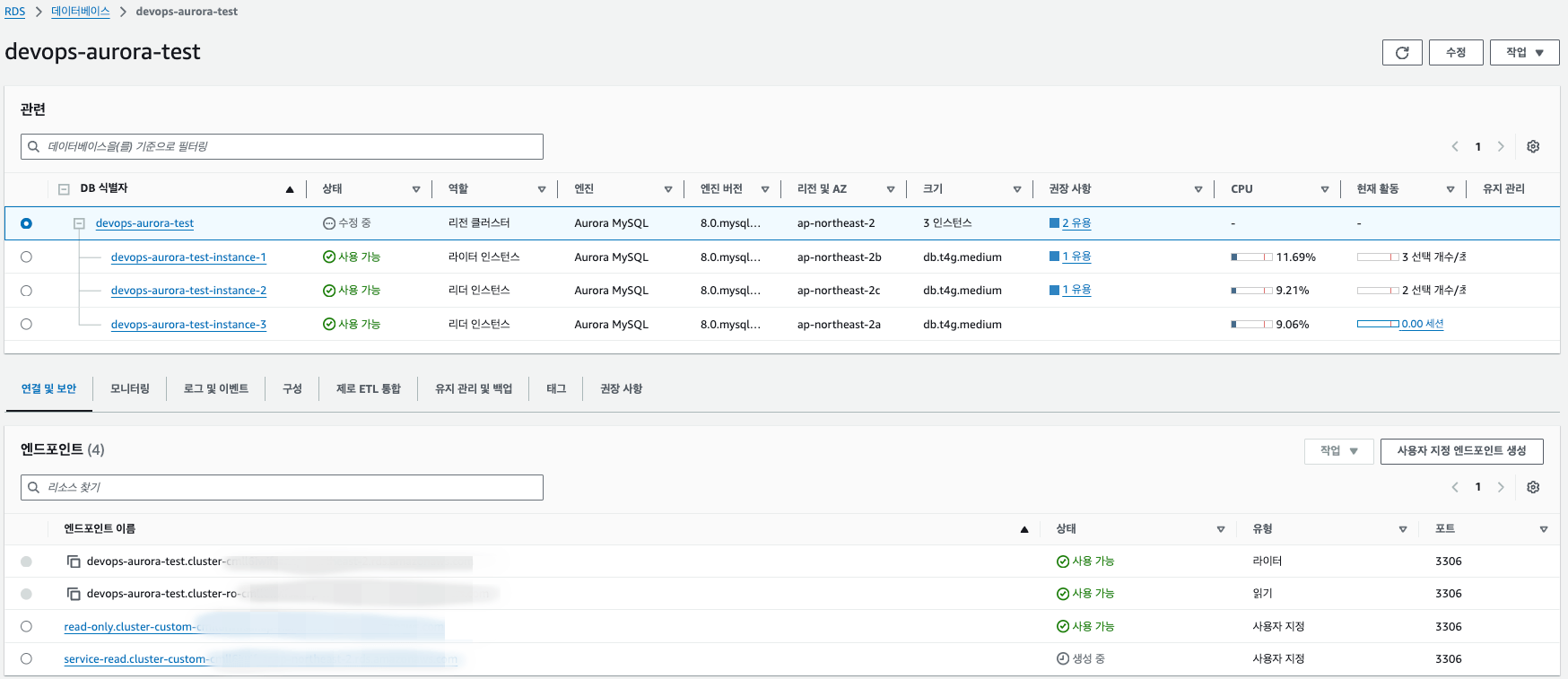
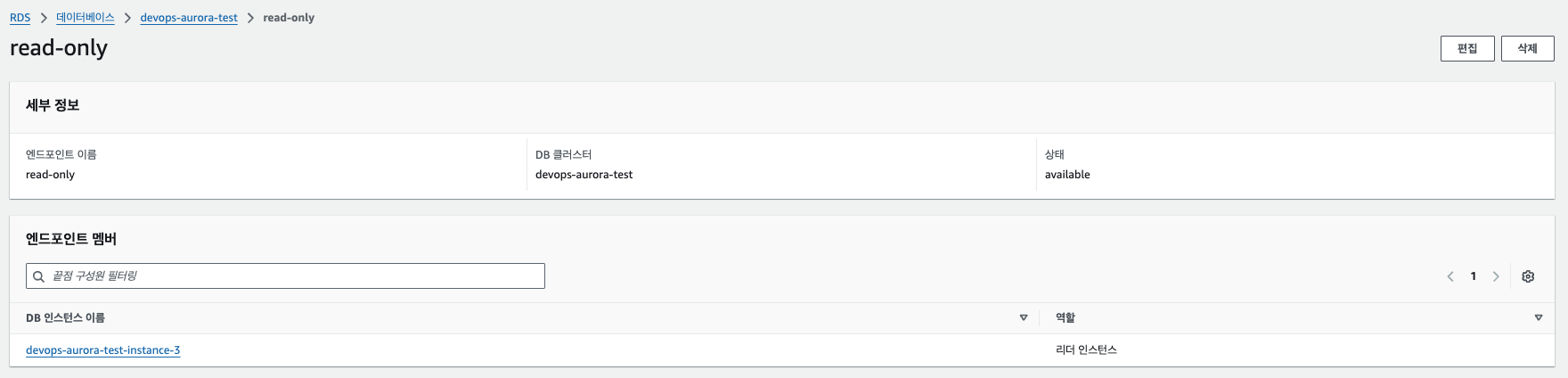
7.Read-Only 커스텀 엔드포인트를 확인해보면 3번 인스턴스만 있는것을 확인 할수 있음
8. Service-read 커스텀 엔드포인트에 가보면 2번 인스턴스만 있는데, 1번인 RW 기능을하는 마스터 노드로 동작하고 있기 때문. 위에서 service-read에 향후 인스턴스 추가시 이 엔드포인트에 추가를 설정했기 때문에 새로운 인스턴스는 모두 service-read에 자동으로 추가.
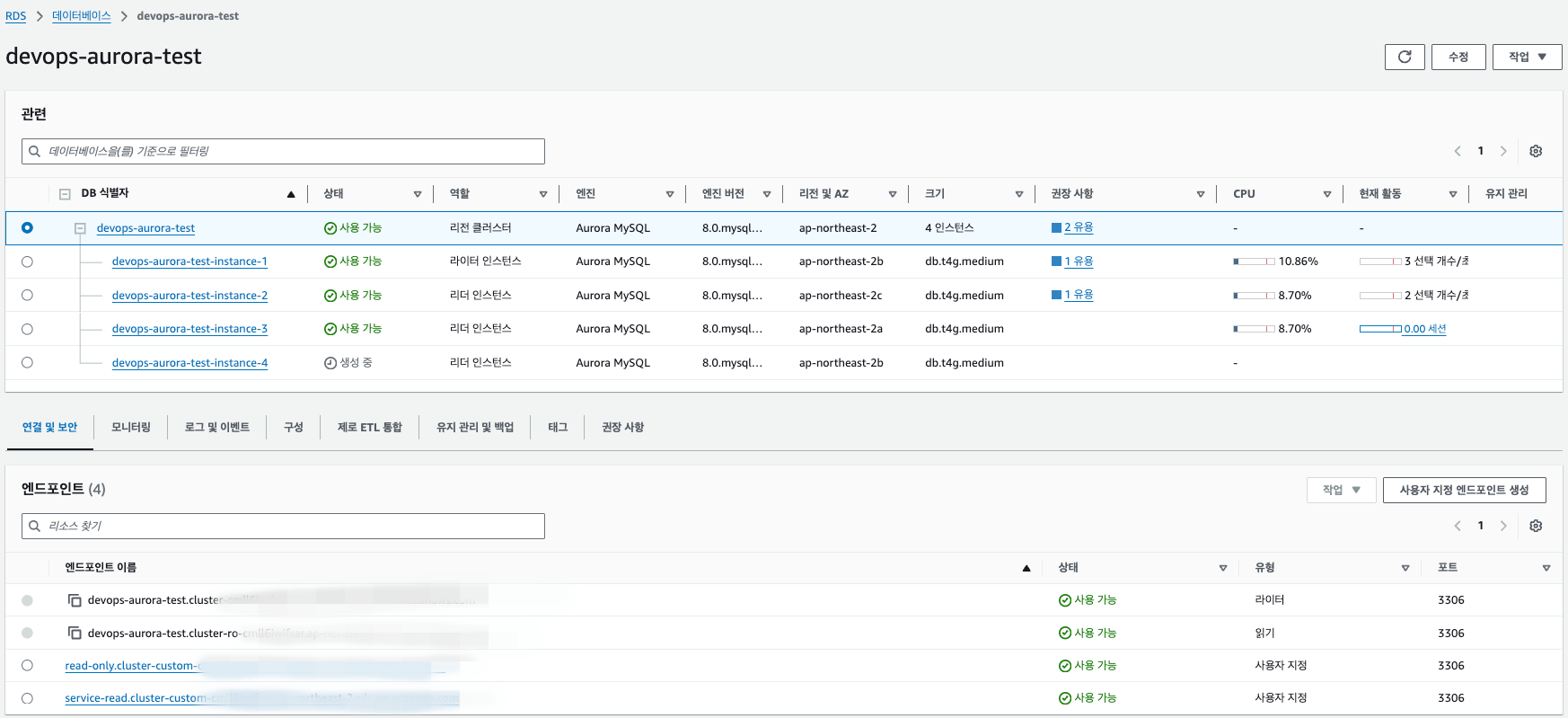
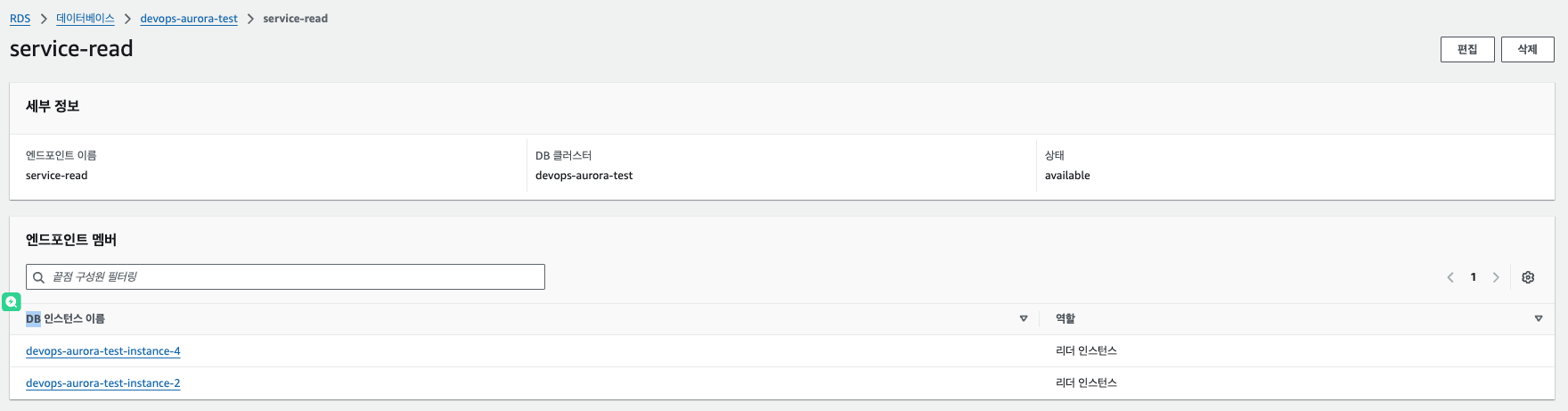
9. 페일오버를 통해 다른 인스턴스가 마스터로 올라갔을시 기존 마스터가 읽기 엔드포인트에 들어오는지 확인. (RW – 1번에서 4번으로 페일오버)
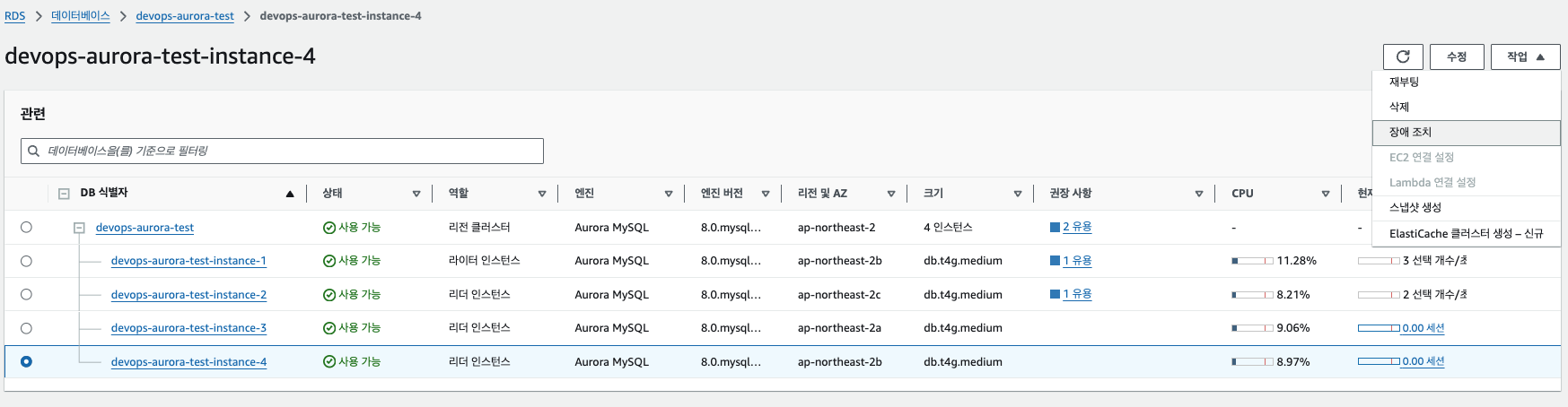
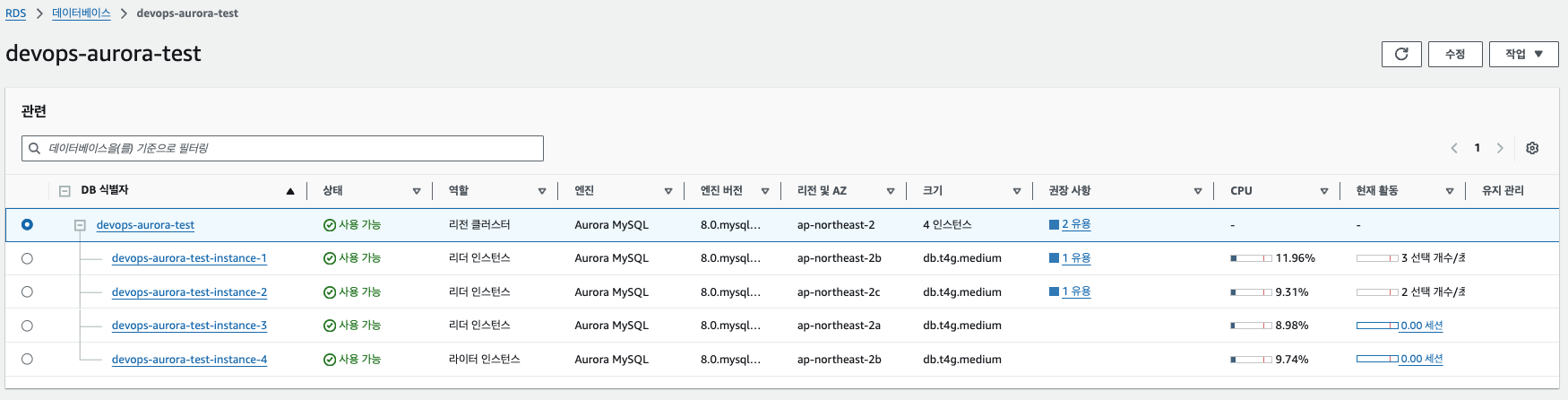
10. 커스텀 엔드포인트에 기존 마스터 노드가 들어와 있는지 확인 (4번이 RW로 승격함에 따라 멤버가 2,4 노드가 1,2 노드로 변경)
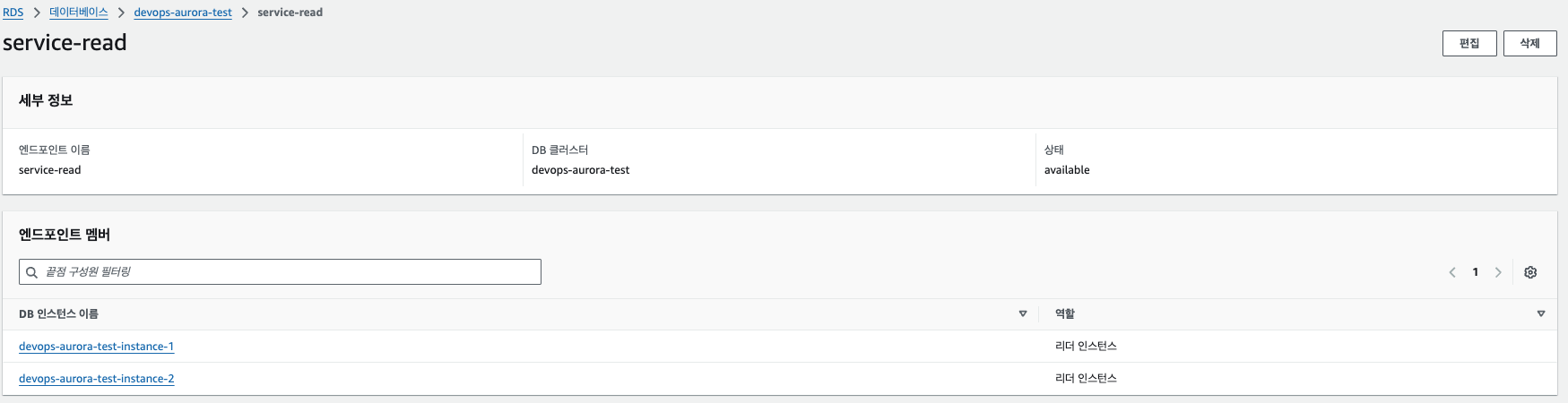
11. Instance-3번의 수정에 들어가 장애조치 우선순위를 낮춰서 마스터로 승격되지 않게 처리
AWS CLI를 이용한 생성 방법
내부용(배치용) 엔드포인트 생성
aws rds create-db-cluster-endpoint \ --db-cluster-identifier devops-aurora-test \ --db-cluster-endpoint-identifier read-only \ --endpoint-type READER \ --static-members devops-aurora-test-instance-3
서비스 읽기용 엔드포인트 생성
aws rds create-db-cluster-endpoint \ --db-cluster-identifier devops-aurora-test \ --db-cluster-endpoint-identifier service-read \ --endpoint-type READER \ --excluded-members devops-aurora-test-instance-3
2.3. 애플리케이션 설정
연결 풀링 권장 설정
최소 연결 수: 10 최대 연결 수: 100 연결 타임아웃: 30초 유휴 연결 제거: 300초
분석용 쿼리 최적화 설정
SET session_replication_role = 'replica'; SET statement_timeout = '3600s';
3. 커스텀 엔드포인트 활용의 장점
3.1. 성능 최적화
워크로드 분리
- 장시간 실행 쿼리와 빠른 응답 쿼리의 분리
- 리소스 경합 최소화
- 쿼리 타임아웃 설정의 유연성
캐시 효율성
- 워크로드별 버퍼 풀 최적화
- 캐시 히트율 향상
- 디스크 I/O 감소
3.2. 운영 효율성
모니터링 및 관리
- 워크로드별 독립적인 모니터링
- 리소스 사용량 추적 용이
- 장애 원인 신속 파악
확장성
- 워크로드별 독립적인 스케일링
- 비용 효율적인 리소스 관리
- 트래픽 피크 대응
3.3. 비용 최적화
- SQL Proxy 비용 절감
- 워크로드에 최적화된 인스턴스 선택
- 리소스 활용도 극대화
3.4. 보안 강화
- 엔드포인트별 보안 그룹 설정
- IP 기반 접근 제어
- IAM 인증 통합
- 워크로드별 감사 로그 분리
4. 운영 및 모니터링
4.1. 핵심 모니터링 지표
- CPU 사용률
- 메모리 사용량
- IOPS
- 지연 시간
- 쓰레드 수
- 연결 수
4.2. 권장 알림 설정
성능 관련 - CPU 사용률 > 80% - 가용 메모리 < 20% - 평균 지연 시간 > 100ms 연결 관련 - 활성 연결 수 > 설정된 임계값 - 연결 거부 발생 - 연결 타임아웃 발생
5. 결론 및 베스트 프랙티스
AWS Aurora의 커스텀 엔드포인트를 활용하면 SQL Proxy 없이도 효율적인 워크로드 분리가 가능합니다. 이를 통해 다음과 같은 이점을 얻을 수 있습니다:
5.1. 설계 원칙
- 워크로드 특성에 따른 명확한 분리
- 확장성을 고려한 구성
- 자동화된 관리 체계 구축
5.2. 운영 체크리스트
- 정기적인 성능 모니터링
- 보안 설정 검토
- 비용 최적화 리뷰
- 장애 대응 시나리오 검증
AWS Aurora의 커스텀 엔드포인트 기능을 활용하면 SQL Proxy 없이도 내부 조회용 인스턴스와 서비스 읽기 인스턴스 그룹을 효과적으로 나눌 수 있습니다. 이를 통해 데이터베이스 성능을 최적화하고, 관리의 용이성을 높일 수 있습니다.
이러한 베스트 프랙티스를 따르면서 커스텀 엔드포인트를 구성하면, 안정적이고 효율적인 데이터베이스 운영이 가능합니다. 특히 대규모 시스템에서는 이러한 세부적인 최적화가 전체 시스템의 성능과 안정성에 큰 영향을 미칠 수 있으므로, 신중한 계획과 구현이 필요합니다.
최신 댓글