
Galera cluster for MySQL 8 – #.1 Architecture

Galera cluster
Galera cluster는 코더십이 만든 동기식 멀티 마스터 복제 기법입니다. 인증 기반 복제(Certification-Based Replication) 방식을 사용하며, 데이터의 완전성을 자동으로 관리해줍니다. 그리고 현재 Galera cluster는 MySQL, MariaDB 그리고 Percona XtraDB 까지도 클러스터를 구성할 수 있습니다. 글을 작성하는 현재 시점에는 4.9 버전까지 릴리즈 되었고, 4.9버전은 MySQL 8.0.25 그리고 MariaDB 10.6버전까지 지원합니다. 예전에 포스팅 한적이 있지만, 최근 버전에서 많은 변경점이 있어 다시 한번 정리를 해보았습니다. 그리고 Galera cluster를 이해하기 앞서, 짚고 넘어가야 하는 부분들을 추가적으로 정리해 보겠습니다.
데이터베이스 리플리케이션에 대한 이해
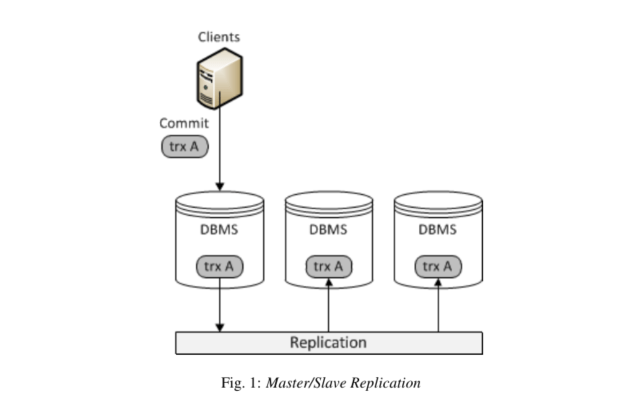
많은 데이터베이스 관리 시스템(DBMS)이 고가용성 시스템을 구축하는데 있어 데이터베이스를 복제하는 방식을 사용합니다. 그 중에서도 가장 많이 사용하는 방식은 Master/Slave 방식입니다. 이러한 M/S 구조에서는 마스터 데이터베이스 서버가 쓰기작업(Insert,Update,Delete)을 한 후에 그것들을 기록한 로그를 네트워크를 통해 슬레이브로 전파합니다. 슬레이브 데이터베이스 노드는 마스터로부터 업데이트 스트림을 수신하고 변경사항을 적용하게 됩니다.
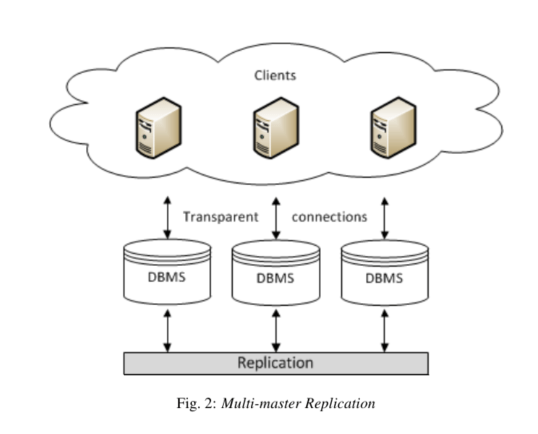
또 다른 복제 방법으로는 모든 노드가 마스터로 작동하는 멀티 마스터 복제 사용할 수도 있습니다. 멀티 마스터 복제 시스템에서는 모든 데이터베이스 노드에서 쓰기작업을 할 수 있으며, 쓰기작업이 발생하면 변경된 내용을 네트워크를 통해 다른 데이터베이스 노드로 전파합니다. 모든 노드가 마스터 노드가 되지만, M/S 구조에서 처럼 단방향 통신이 아니기 때문에 노드간의 데이터 변경사항이 모든 노드에 전파가 되었는지, 데이터 정합성은 맞는지 체크하는 것이 중요합니다.
비동기식 복제와 동기식 복제
다른 노드가 서로 어떻게 관련되는지 설정하는 것 외에도 클러스터를 통해 데이터베이스 트랜잭션을 전파하는 방법에 대한 프로토콜도 있습니다.
동기식 복제
데이터 변경 사항을 즉시 복제합니다. 노드는 단일 트랜잭션에서 모든 복제 노드로 업데이트하며, 모든 복제 노드가 동기화된 상태로 유지됩니다. 즉, 트랜잭션이 커밋되면 모든 노드가 동일한 값을 갖습니다.
비동기식 복제
지연된 복제 방식을 사용합니다. 마스터 데이터베이스는 복제본 업데이트를 다른 노드에 비동기식으로 전파합니다. 마스터 노드가 복제본을 전파한 후 트랜잭션이 커밋됩니다. 즉, 트랜잭션이 커밋될 때 적어도 짧은 시간 동안 일부 노드는 다른 값을 보유합니다.
동기식 복제의 장점
이론적으로 동기식 복제는 비동기식 복제에 비해 몇 가지 장점이 있습니다. 예를 들어:
- 고가용성 클러스터를 제공하고 연중무휴 서비스 가용성을 보장
- 노드 충돌 시 데이터 손실이 없음
- 데이터 복제본은 일관성을 유지
- 장애 조치를 하는데 있어 복잡하고 시간이 많이 소요되는 경우가 적음
- 동기식 복제를 사용하면 클러스터의 모든 노드에서 트랜잭션을 서로 병렬로 실행할 수 있으므로 성능이 향상
- 클러스터 전반에 걸친 인과관계 동기 복제는 전체 클러스터에 대한 인과관계를 보장. 예를 들어, 트랜잭션 후에 실행된 SELECT 쿼리는 다른 노드에서 실행된 경우에도 항상 트랜잭션의 결과를 보장
동기식 복제의 단점
- 즉시 복제 프로토콜은 한 번에 한 작업씩 노드를 조정합니다. 이 때 2 Phase commit 또는 분산 잠금을 사용합니다.
- 하나의 시스템은 프로세스가 작업(𝑜)으로 인해 동작하는 노드 수(𝑛), 초당 트랜잭션의 처리량(𝑡)을 참조하여 초당 메시지(𝑚)를 제공합니다.
𝑚 = 𝑛 × 𝑜 × 𝑡이 것이 의미하는 바는 노드 수가 증가하면 트랜잭션 응답 시간과 충돌 및 교착 상태 비율이 기하급수적으로 증가한다는 의미입니다. 이러한 동기식 복제의 단점 때문에 MySQL 및 PostgreSQL과 같이 널리 채택된 오픈 소스 데이터베이스는 비동기 복제 솔루션만 제공합니다.
동기식 복제 문제 해결
위에 나열한 동기식 복제 시스템의 단점들 때문에 데이터베이스를 개발사들은 동기식 데이터베이스 복제에 대한 대안을 제안하기 시작했습니다. 이론을 정립하는 것 이외에도 다양한 프로토타입을 구현하여 많은 가능성을 보여주었습니다. 다음은 이러한 연구가 가져온 가장 중요한 개선 사항 중 일부입니다.
- Group communication : 데이터베이스 노드의 통신을 위한 패턴을 정의하는 고급 추상화 방식입니다. 복제 데이터의 일관성을 보장합니다.
- Write-sets : 단일 Write-sets 메시지에서 데이터베이스 쓰기를 묶습니다. 노드의 조정을 한 번에 한 작업으로 제한합니다.
- Database state machine : 사이트에서 데이터베이스 로컬로 읽기 전용 트랜잭션을 처리합니다. 업데이트 트랜잭션의 이행은 먼저 데이터베이스 사이트에서 로컬로 실행한 다음 얉은 복사(shallow-copy)를 하고, 인증 및 가능한 커밋을 위해 다른 데이터베이스 사이트에 Read-sets로 브로드캐스트 됩니다.
- Transaction Reordering : 데이터베이스 사이트에서 커밋하기전에 트랜잭션을 재정렬 하고 다른 데이터베이스 사이트로 브로드캐스트 합니다. 인증 테스트를 성공적으로 통과한 트랜잭션만 수를 증가시킵니다.
인증기반 복제(Certification-Based Replication)
맨처음 소개에 Galera cluster는 인증기반 복제를 사용한다고 했습니다. 인증기반 복제는 Group communication 및 Transaction Reordering을 사용하여 동기식 복제를 합니다. 트랜잭션은 단일 노드 또는 복제본에서 낙관적(트랜잭션이 발생하는 동안 동일한 데이터에 대해 다른 트랜잭션이 발생하지 않을 것이라고 여기는 것)으로 실행된 다음 커밋 시 조정된 인증 프로세스를 실행하여 글로벌 일관성을 적용합니다. 경합과정에 있는 모든 글로벌 트랜잭션의 순서를 구축하는 브로드캐스트 서비스의 도움을 받아 글로벌 정합성을 유지합니다. 인증기반 복제를 구성하기 위해서는 몇가지 특정 기능들이 필요합니다.
- Transactional Database : 반드시 트랜잭션을 보장해야하며, UNCOMMIT된 데이터는 Rollback 할 수 있어야 합니다.
- Atomic Changes : 데이터베이스를 원자성을 가지고 변경할 수 있어야 합니다. 트랜잭션에서 모든 노드에 일련의 데이터베이스 작업이 발생해야 합니다. 모든 노드에 적용될 수 없다면 아무 일도 발생하지 않습니다.
- Global Ordering : 복제 셋에 포함된 노드를 모두 포함하여 순서가 지정되어야 합니다. 모든 인스턴스에 동일한 순서로 적용됩니다.
인증기반 복제는 다음과 같이 동작합니다.
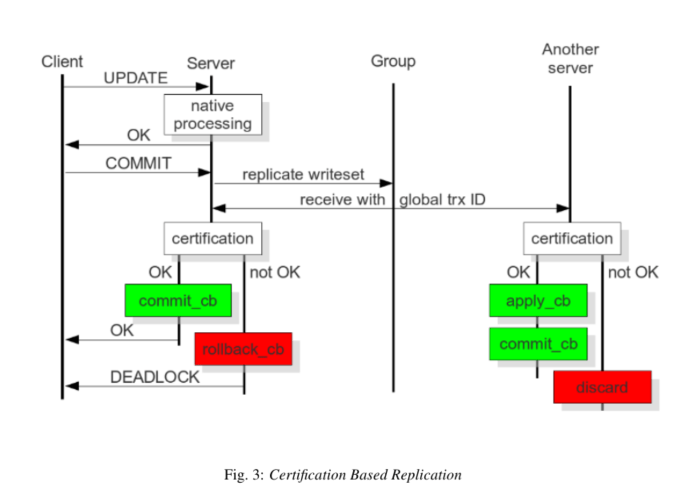
- 클라이언트가 COMMIT 명령을 실행했지만 실제 COMMIT이 발생하기 전에 변경된 행의 기본 키와 트랜잭션에 의해 데이터베이스에 적용된 모든 변경 사항이 Write-sets로 수집됩니다.
- 데이터베이스는 이 Write-sets를 다른 모든 노드로 보냅니다.
- Write-sets는 기본 키를 사용하여 결정적 인증 테스트를 거칩니다.
- Write-sets를 시작하는 노드를 포함하여 클러스터의 각 노드에서 수행됩니다.
- 노드가 Write-sets를 적용할 수 있는지 여부를 결정합니다.
- 인증 테스트가 실패하면 노드는 Write-sets를 삭제하고 클러스터는 원래 트랜잭션을 롤백합니다. 그러나 테스트가 성공하면 트랜잭션이 COMMIT 되고 Write-sets가 나머지 클러스터에 적용됩니다.
Galera Cluster의 인증기반 복제는 글로벌 트랜잭션 순서에 따라 영향을 받습니다. Galera Cluster가 복제를 진행하는 동안 각각의 트랜잭션에 시퀀스 넘버를 부여합니다. 트랜잭션이 COMMIT 지점에 도달하면 노드는 마지막으로 성공한 트랜잭션의 시퀀스 넘버와 비교하여 확인합니다. 이 간격 내에서 발생하는 트랜잭션이 서로의 영향력을 알 수 없다는 것을 감안할 때, 둘 사이의 간격에 주의해야 합니다. 이 간격의 모든 트랜잭션에서 해당 트랜잭션과의 기본 키 충돌이 있는지 확인하며 충돌이 감지되면 인증 테스트가 실패합니다. 모든 트랜잭션 처리 절차는 동일하고, 복제된 트랜잭션 역시 동일한 순서로 적용됩니다. 따라서 모든 노드가 가지는 트랜잭션의 결과는 동일합니다. 트랜잭션을 시작한 노드는 COMMIT 했는지 여부를 클라이언트에 알릴 수 있습니다.
Galera Cluster의 복제 API
동기식 복제 시스템은 일반적으로 즉시 복제를 사용합니다. 클러스터의 노드는 단일 트랜잭션을 통해 복제본을 업데이트하여 다른 모든 노드와 동기화합니다. 이는 트랜잭션이 COMMIT 될 때 모든 노드가 동일한 값을 가짐을 의미합니다. 이 프로세스는 그룹 통신을 통한 Write-sets 복제를 사용하여 발생합니다. Galera Cluster의 내부 아키텍처는 다음 네 가지 구성 요소를 중심으로 이루어집니다.

- DBMS(데이터베이스 관리 시스템) : 개별 노드에서 실행되는 데이터베이스 서버입니다. Galera Cluster는 MySQL, MariaDB 또는 Percona XtraDB를 사용할 수 있습니다.
- wsrep API : 이것은 데이터베이스 서버에 대한 인터페이스이며 복제 공급자입니다. 두 가지 주요 요소로 구성됩니다.
wsrep Hooks: Write-sets 복제를 위해 데이터베이스 서버 엔진과 통합됩니다.
dlopen(): 이 함수는 wsrep 후크에서 wsrep 공급자를 사용할 수 있도록 합니다. - Galera Replication Plugin : 이 플러그인은 Write-sets 복제 서비스 기능을 활성화합니다.
- GroupCommunicationPlugins : GaleraCluster에 사용할 수 있는 여러 그룹 통신 시스템(예: gcomm 및 Spread).
wsrep api
wsrep API는 데이터베이스용 일반 복제 플러그인 인터페이스입니다. 애플리케이션 콜백 및 복제 플러그인 호출 세트를 정의합니다.
wsrep API는 데이터베이스 서버를 상태로 간주하는 복제 모델을 사용합니다. 해당 상태는 데이터베이스의 내용을 나타냅니다. 데이터베이스가 사용 중이고 클라이언트가 데이터베이스 콘텐츠를 수정하면 해당 상태가 변경됩니다. wsrep API는 데이터베이스 상태의 변경을 일련의 원자적 변경 또는 트랜잭션으로 나타냅니다.
데이터베이스 클러스터에서 모든 노드는 항상 동일한 상태를 갖습니다. 동일한 직렬 순서로 상태 변경을 복제하고 적용하여 서로 동기화합니다. 보다 기술적인 관점에서 Galera Cluster는 다음과 같은 방식으로 상태 변경을 처리합니다.
- 클러스터의 한 노드에서 데이터베이스의 상태 변경이 발생합니다.
- 데이터베이스에서 wsrep 후크는 변경 사항을 쓰기 집합으로 변환합니다.
- dlopen()은 wsrep 후크에서 wsrep 공급자 기능을 사용할 수 있도록 합니다.
- Galera 복제 플러그인은 Write-sets 인증 및 클러스터 복제를 처리합니다.
클러스터의 각 노드에 대해 응용 프로그램 프로세스는 우선 순위가 높은 트랜잭션에 의해 발생합니다.
GTID (Global Transation ID)
클러스터 전체에서 동일한 상태를 유지하기 위해 wsrep API는 GTID를 사용합니다. 이를 통해 상태 변경을 식별하고 마지막 상태 변경과 관련하여 현재 상태를 식별할 수 있습니다. 다음은 GTID의 예입니다.
45eec521-2f34-11e0-0800-2a36050b826b:94530586304
글로벌 트랜잭션 ID는 다음 구성 요소로 구성됩니다.
- 상태 UUID 상태에 대한 고유 식별자이며 상태가 변경되는 순서입니다.
- 서수 시퀀스 번호: seqno는 시퀀스의 변경 위치를 나타내는 데 사용되는 64비트 부호 있는 정수입니다.
글로벌 트랜잭션 ID를 사용하면 애플리케이션 상태를 비교하고 상태 변경 순서를 설정할 수 있습니다. 이를 사용하여 변경 사항이 적용되었는지 여부와 변경 사항이 주어진 상태에 적용 가능한지 여부를 확인할 수 있습니다.
Galera Replication Plugin
Galera Replication Plugin은 wsrep API를 구현합니다. wsrep 공급자로 작동합니다. 보다 기술적인 관점에서 Galera 복제 플러그인은 다음 구성 요소로 구성됩니다.
- Certification Layer: 이 계층은 Write-sets를 준비하고 이에 대한 인증 확인을 수행하여 적용할 수 있는지 확인합니다.
- Replication Layer: 이 계층은 복제 프로토콜을 관리하고 전체 주문 기능을 제공합니다.
- Group Communication Framework: 이 계층은 Galera Cluster에 연결하는 다양한 그룹 통신 시스템을 위한 플러그인 아키텍처를 제공합니다.
Group Communication Plugins
그룹 커뮤니케이션 프레임워크는 다양한 gcomm 시스템을 위한 플러그인 아키텍처를 제공합니다.
Galera Cluster는 가상 동기화 QOS(Quality of Service)를 구현하는 단일 그룹 통신 시스템 계층 위에 구성됩니다. 가상 동기화는 일관성을 보장하지만 원활한 다중 마스터 작업에 필요한 시간적 동기화를 보장하지는 않습니다. 이 문제를 해결하기 위해 Galera Cluster는 자체 런타임 구성 가능 시간 흐름 제어를 구현합니다. 흐름 제어는 노드 동기화를 1초 미만으로 유지합니다.
그룹 커뮤니케이션 프레임워크는 또한 여러 소스에서 메시지의 전체 순서를 제공합니다. 이를 사용하여 다중 마스터 클러스터에서 글로벌 트랜잭션 ID를 생성합니다.
전송 수준에서 Galera Cluster는 대칭 무방향 그래프입니다. 모든 데이터베이스 노드는 TCP(전송 제어 프로토콜) 연결을 통해 서로 연결됩니다. 기본적으로 TCP는 메시지 복제와 클러스터 구성원 서비스 모두에 사용됩니다. 그러나 LAN(Local Area Network)에서 복제를 위해 UDP(User Datagram Protocol) 멀티캐스트를 사용할 수도 있습니다.
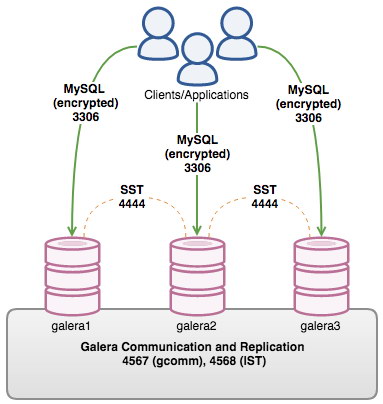
State Transfer
클러스터에서 개별 노드로 데이터를 복제하여 노드를 클러스터와 동기화하는 프로세스를 프로비저닝이라고 합니다. Galera Cluster에서 노드를 프로비저닝하는 데 사용할 수 있는 두 가지 방법이 있습니다.
- State Snapshot Transfer (SST)
- Incremental State Transfer (IST)
SST (State Snapshot Transfers)
Galera Cluster는 Snapshot을 wsrep모듈을 통해 전송합니다. 새 노드가 클러스터에 참여하면 클러스터의 데이터를 요청합니다. 제공자(donor)로 알려진 한 노드는 SST(State Snapshot Transfer) 메소드를 사용하여 Joiner라고하는 새 노드에 전체 데이터 사본을 제공합니다. wsrep_sst_donor 파라미터로 어떤 노드를 donor로 할지 미리 지정할 수 있습니다. Donor Node를 설정하지 않으면 Group Communication 모듈은 노드 상태에 대해 사용 가능한 정보를 기반으로 Donor를 선택합니다. Group Communication 모듈은 흐름 제어, 상태 전송 및 쿼럼 계산을 위해 노드 상태를 모니터링합니다. JOINING으로 표시되는 노드가 흐름 제어 및 쿼럼에 포함되지 않도록 합니다.
노드는 SYNCED 상태일 때 donor 역할을 할 수 있습니다. Joiner 노드는 사용 가능한 동기화된 노드에서 donor를 선택합니다. 동일한 gmcast.segment wsrep 공급자 옵션이 있는 동기화된 노드에 대한 기본 설정을 표시하거나 인덱스에서 첫 번째를 선택합니다. donor 노드가 선택되면 상태가 즉시 DONOR로 변경됩니다. donor로 선택이 되면 더 이상 요청에 사용할 수 없습니다.
Galera는 상태 스냅 샷 전송에 사용할 여러 백엔드 방법을 지원합니다. 두 가지 유형이 있습니다. 데이터베이스 서버와 클라이언트를 통해 인터페이스하는 Logical State Snapshots 및 노드에서 노드로 직접 데이터 파일을 복사하는 Physical State Snapshots가 있습니다.
| Method | Speed | Blocks Donor | Available on Live Node | Type | DB Root Access |
|---|---|---|---|---|---|
| mysqldump | Slow | Blocks | Available | Logical | Donor and Joiner |
| rsync | Faster | Blocks | Unavailable | Physical | None |
| xtrabackup | Fast | Briefly | Unavailable | Physical | Donor only |
| clone | Fastest | on DDLs | Unavailable | Physical | Donor only |
처음 Galera cluster가 나왔을 때 스냅샷 전송 Method는 mysqldump, rsync, xtrabackup 세가지였지만, 현재는 정말 많은 전송 Method를 선택할 수 있습니다. 가장 최근에 clone Method가 추가되었는데, mysql 8.0.22 버전부터 사용할 수 있으며 현재는 rsync보다 빠르고, DDL를 사용할 때를 제외하고는 Donor 노드를 Block하지 않습니다. 당연히 최신 버전에서는 clone method를 사용하는 것이 성능적인 면에서 좋을 것이라고 생각합니다.
- Logical State Snapshots : mysqldump
- Physical State Snapshots : rsync, xtrabackup, xtrabackup-v2, mariabackup, clone
Logical State Snapshots의 특징
- 운영중인 DB에서 사용 가능하며 초기화된 스토리지 엔진에도 적용이 가능합니다.
- Donor와 Joiner가 다른 구성을 가져도 상관없기 때문에 스토리지 엔진을 업그레이드 한다거나 다른 옵션을 적용할 때 사용 가능합니다.
- 속도가 매우 느립니다.
- 잠재적으로 Donor 노드가 될 수 있는 다른 노드에 root 엑세스가 가능하도록 구성을 해야합니다.
Physical State Snapshots의 특징
- 한 노드에서 다른 노드의 디스크로 데이터를 물리적으로 복사하므로 데이터베이스 노드와 상호 작용할 필요가 없습니다.
- Donor 노드가 Joiner 노드의 데이터에 덮어 쓰기 때문에 Joiner 노드가 Online 상태가 아니여도 상관 없습니다.
- 속도가 빠릅니다.
- Donor와 Joiner 가 모두 같은 스토리지 엔진을 사용해야 합니다.
- 스토리지 엔진이 초기화된 상태라면 사용할 수 없습니다. 즉, SST 전송에 필요한 설정들 및 donor 노드가 가지고 있는 설정들을 적용한 후 재구동 해야합니다. 스토리지 엔진 없이는 인증을 수행할 수 없기 때문에 상태 스냅샷 전송이 완료될 때까지 클라이언트가 액세스할 수 없습니다.
rsync
물리적 스냅샷 전송의 모든 장점과 단점을 가지고 있습니다. 전송하는 동안 donor 노드를 차단하지만 rsync는 데이터베이스 구성이나 Root 액세스가 필요하지 않으므로 구성이 더 쉽습니다. 테라바이트 규모의 데이터베이스를 사용할 때 rsync는 xtrabackup보다 상당히 빠릅니다(1.5~2배 빠름). 이를 통해 전송 시간이 몇 시간 단축됩니다. rsync는 rsync 델타 전송 알고리즘과 관련된 rsync-wan 수정 기능도 갖추고 있습니다. 그러나 이로 인해 I/O가 더 많이 소모된다는 점을 감안할 때, 일반적인 WAN 배포에서 네트워크에 병목현상이 있는 경우에만 사용을 권장합니다.
Donor 노드와 Joiner 노드의 rsync 버전에도 영향을 받습니다.
xtrabackup
가장 인기 있는 SST는 xtrabackup입니다. 물리적 상태 스냅샷의 모든 장점과 단점을 가지고 있지만 사실상 donor 노드는 차단되지 않습니다. xtrabackup은 MyISAM 테이블(예: 시스템 테이블)을 복사하는 데 걸리는 짧은 시간 동안만 donor를 차단합니다. 시스템 테이블이 작으면 차단 시간이 매우 짧습니다. 그러나 이런 이유로 xtrabackup을 사용하는 상태 스냅샷 전송은 rsync를 사용하는 것보다 상당히 느릴 수 있습니다. xtrabackup이 가능한 한 짧은 시간에 많은 양의 데이터를 복사한다는 점을 감안할 때 Donor 성능이 눈에 띄게 저하될 수도 있습니다.
clone
기본 MySQL 클론 플러그인을 기반으로 합니다. xtrabackup보다 훨씬 빠른 것으로 판명되었지만 전송 중에 DDL이 발생하면 Donor 노드를 차단합니다.
IST (Incremental State Transfer)
IST에서 클러스터는 Joiner에서 누락된 트랜잭션을 식별하여 노드를 프로비저닝하고 전체 스냅샷이 아닌 해당 트랜잭션만 보냅니다. 이 프로비저닝 방법은 특정 조건에서만 사용할 수 있습니다.
- Joiner Node 상태 UUID가 그룹의 것과 동일한 경우
- Donor의 write-sets 캐시(GCache)에서 누락된 모든 write-sets 캐시를 사용할 수 있는 경우
이러한 조건이 충족되면 donor 노드는 누락된 트랜잭션만 전송하고 Joiner가 클러스터를 따라 잡을 때까지 순서대로 재생합니다.
IST의 장점은 노드를 클러스터에 재결합 하는 속도를 크게 높일 수 있고 이러한 프로세스에서는 Donor가 차단되지 않습니다.
IST에 대한 가장 중요한 매개변수는 Donor 노드의 gcache.size입니다. 이 것은 Write-sets를 캐싱하기 위해 시스템 메모리에 할당하는 공간을 제어합니다. 사용 가능한 공간이 많을수록 더 많은 Write-sets를 저장할 수 있습니다. Write-sets가 많을수록 IST를 통해 더 넓은 범위의 seqno 간격을 저장할 수 있습니다. 반면에 Write-sets 캐시가 데이터베이스 상태 크기보다 훨씬 크면 IST가 SST보다 효율성이 떨어집니다.
Write-sets cache (GCache)
Galera Cluster는 Write-sets cache 또는 GCache라는 특수 캐시에 Write-sets를 저장합니다. GCache 캐시는 Write-sets 대한 메모리를 할당 합니다. 주요 목적은 Random Access Memory의 쓰기 설정 공간을 최소화하는 것입니다. Galera Cluster는 Write-sets 스토리지를 디스크로 오프로드하여 이를 개선합니다. GCache는 세 가지 유형의 스토리지를 사용합니다.
- Permanent In-Memory Store : 물리적인 메모리에 여유가 있을때 메모리를 사용합니다. 크기 제한이 있으며, 기본값은 비활성화 상태입니다.
- Permanent Ring-Buffer File : Write-sets는 캐시 초기화 시에 미리 디스크에 할당합니다. 기본 Write-sets 저장소로 사용하며 기본값은 128Mb입니다.
- On-Demand Page Store : Write-sets를 필요에 따라 런타임 동안 메모리에 매핑된 페이지 파일에 할당합니다. 기본값은 128Mb이지만 더 큰 Write-sets를 저장해야 하는 경우 더 커질 수 있습니다. 페이지 저장소의 크기는 사용 가능한 디스크 공간에 의해 제한됩니다. 기본적으로 Galera Cluster는 사용하지 않을 때 페이지 파일을 삭제하지만 보관할 페이지 파일의 총 크기에 제한을 설정할 수 있습니다. 다른 모든 저장소가 비활성화 상태이면 디스크에 하나 이상의 페이지 파일이 남게 됩니다.
GCache는 Permanent In-Memory Store -> Permanent Ring-Buffer File -> On-Demand Page Store 순으로 할당됩니다.
Galera Cluster는 Flow Control이라는 피드백 메커니즘을 사용하여 복제 프로세스를 관리합니다. 흐름 제어를 통해 노드는 필요에 따라 복제를 일시 중지하고 재개할 수 있습니다. 이렇게 하면 트랜잭션을 적용할 때 노드가 다른 노드보다 너무 뒤쳐지는 것을 방지할 수 있습니다. 이 것에 대한 설명은 다음 포스팅에서 이어 하겠습니다.
쓰다보니 엄청 길어졌네요. 기본적인 갈레라 클러스터의 아키텍처를 정리해 보았습니다. 이어지는 포스팅에서 갈레라 클러스터 구성, 복제의 플로우 컨트롤, 장애와 리커버리 등을 계속 정리할 예정입니다.
최신 댓글