
MongoDB Index#.3 Hash Index

MongoDB Index#.3 Hash Index
이전 포스팅
MongoDB의 Hash Index
해시 인덱스는 B-Tree 만큼 범용적이지는 않지만 고유의 특성과 용도를 지닌 인덱스 중에 하나로, 주어진 키 값을 이용하여 목표 레코드의 주소를 직접적으로 계산하는 방식입니다. 따라서 단일 데이터를 가져오는것에는 최적화 되어 있지만, 범위를 검색한다거나, 정렬된 데이터를 가져온다거나 하는 방식에는 사용되지 않습니다. 키 값에 연산(해싱함수)를 적용하여 찾고자 하는 레코드가 있는 위치 주소에 바로 접근합니다. 일반적인 DBMS에서 해시 인덱스는 메모리 기반의 테이블에 주로 구현돼 있으며 디스크 기반의 대용량 테이블용으로는 거의 사용되지 않는다는 특징이 있습니다.
MongoDB에서도 해시 인덱스를 지원하며, MongoDB에서의 해시 인덱스는 쿼리의 검색 성능을 높이는데 사용하기 보다는 해시 샤딩을 구현하기 위해 더 많이 사용합니다.
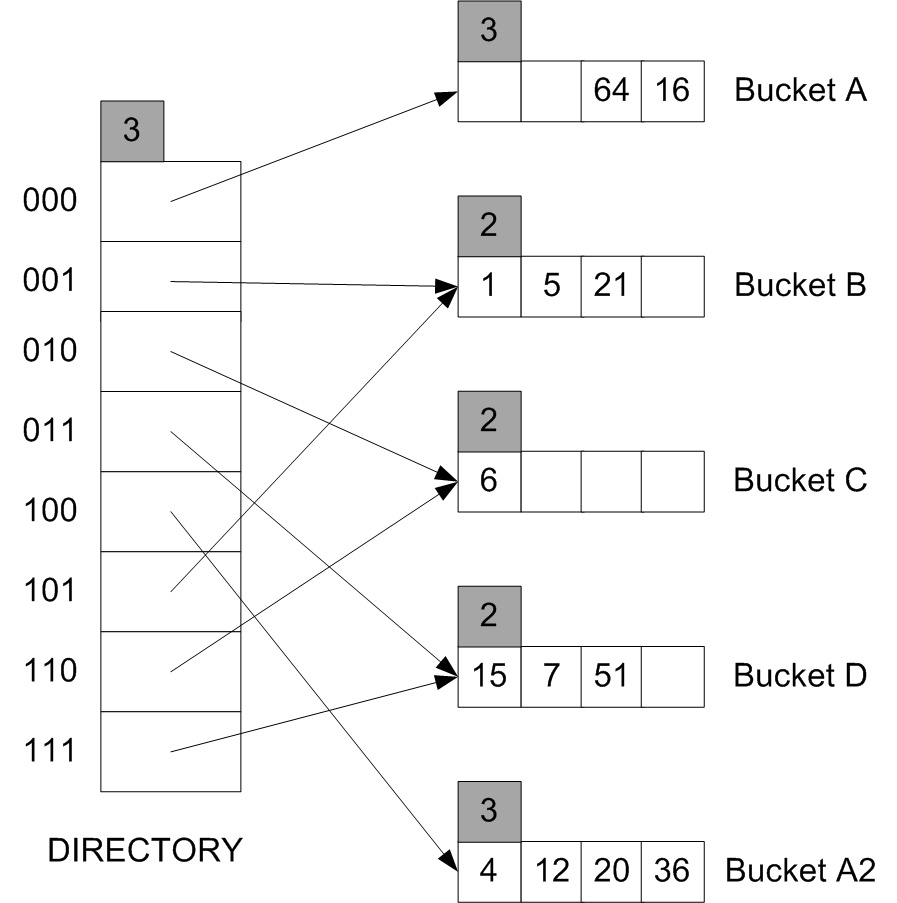
해시 인덱스는 트리구조가 아닌 디렉토리 구조의 인덱스로, 해시 함수를 거쳐 바로 버켓의 주소를 찾아 즉시 그 버켓을 읽어 해당 데이터의 레코드를 가져옵니다. 이렇게 해시 인덱스는 B-Tree 인덱스와는 다르게 키를 찾는 과정이 복잡하지 않으며, 매우 빠르다는 장점이 있습니다.
하지만 MongoDB의 해시 인덱스는 일반적인 DBMS의 해시 인덱스와 조금 다른 구조를 가지고 있습니다.
MongoDB의 소스 코드상에는 실제 해시 인덱스를 구현한 클래스나 자료 구조체가 없고, B-Tree 인덱스에 해시 된 값을 저장합니다. 애플리케이션 단에서는 해시 인덱스처럼 보이고 해시 인덱스의 제한 사항을 그대로 따르지만, 내부적으로는 B-Tree 자료구조를 사용합니다.
해시 인덱스를 제공하지 않는 DBMS에서 해시 인덱스를 에뮬레이션 하는 대표적인 방법이 바로 B-Tree 인덱스에 해시 된 값을 지정하는 방법입니다. 에뮬레이션 방식에서는 해시 인덱스를 생성하고자하는 필드의 해시값을 별도의 필드에 저장하고, 그 필드에 B-Tree 인덱스를 생성합니다. 그리고 해당 데이터 파일에 실제 값과 해시 된 값을 같이 저장하는데, MongoDB에서는 컬렉션에 데이터를 저장하지 않고 해시 인덱스로 생성만 하면 됩니다. 그렇게 하면 해시 인덱스의 키 엔트리에 MD5 해시 된 결과값의 하위 64Bit만으로 구성된 정수값이 저장됩니다.
다음은 MongoDB에서 해시 인덱스를 생성하는 방법입니다.
> db.collection.createIndex( { field: "hashed" } )
암호화 해시(MD5)를 통해서 생성된 값의 8바이트를 정수형으로 변환해서 인덱스 키를 생성하기 때문에 파일의 크기가 작습니다. 인덱스의 크기가 작아지면 메모리를 효율적으로 쓸수 있고, 디스크 I/O도 줄어들게 됩니다.
MongoDB에서는 단일 필드에 대해서만 해시 인덱스를 생성할 수 있습니다.
서브 도큐먼트에 해시값을 생성하는 경우 서브 도큐먼트 전체를 하나의 값으로 보기 때문에 검색하는 필드의 순서가 바뀐다거나 하면 결과나 나오지 않습니다.
MongoDB의 해시 인덱스에 대한 내용은 여기까지 마무리 하겠습니다.
다음 포스트
참고 자료
도서 : 맛있는 몽고DB
도서: Real MongoDB
도서: 오픈소스 몽고DB
도서: MongoDB in Action
MongoDB Manual: https://docs.mongodb.com/manual/
최신 댓글