
MongoDB Data Modeling

MongoDB 데이터 모델링
데이터 모델링의 핵심은 애플리케이션의 요구사항, 데이터베이스 엔진의 성능 특성 및 데이터 검색 패턴의 균형을 맞추는 것입니다. 데이터 모델을 설계 할 때 데이터 자체의 고유 구조 뿐만아니라 데이터의 애플리케이션 사용(즉, 데이터 쿼리, 업데이트 및 처리)을 항상 고려해야 합니다.
MongoDB의 도큐먼트 크기는 16MB로 제한되어 있고, 서브 도큐먼트의 뎁스 역시 100레벨로 제한되어 있습니다. 그렇기 때문에 임베디드와 레퍼런싱(참조)를 적절히 사용해야하며, NoSQL 범주에 포함되어 스키마 프리(schema-free)의 특징을 가지고 있지만, 한번에 조회되는 데이터, 자주 업데이트 되는 데이터 등을 고려해서 모델링을 해야합니다. 관계형 모델링과 비정규화된 모델링을 적절히 섞어 유연한 모델링을 할 수 있는 것이 MongoDB의 가장 큰 특징입니다.
MongoDB 모델링의 특징
유연한 스키마 (Flexible Schema)
데이터를 삽입하기 전에 테이블의 스키마를 결정하고 선언해야하는 SQL 데이터베이스와 달리, MongoDB의 컬렉션은 기본적으로 모든 도큐먼트가 동일한 스키마를 가질 필요가 없습니다.
- 단일 컬렉션의 도큐먼트는 동일한 필드 집합을 가질 필요가 없으며 필드의 데이터 유형은 컬렉션 내의 도큐먼트에 따라 다를 수 있습니다.
- 도큐먼트에 새로운 필드를 추가하는 것 같은, 컬렉션의 도큐먼트 구조를 변경하려면 기존 필드를 제거하거나, 필드 값을 새로운 타입으로 변경하여 도큐먼트를 새로운 구조로 업데이트합니다.
이러한 유연성은 도큐먼트를 엔티티 또는 개체에 쉽게 매핑 할 수 있도록합니다. 도큐먼트가 컬렉션의 다른 도큐먼트와 상당히 다른 경우에도 마찬가지로 각 도큐먼트는 대표 엔티티의 데이터 필드와 매치 할 수 있습니다. 그러나 실제로 컬렉션의 도큐먼트는 유사한 구조를 공유하므로 업데이트 및 삽입 작업 중에 컬렉션에 대한 도큐먼트 유효성 검사 규칙을 적용 할 수도 있습니다.
도큐먼트 구조
MongoDB 애플리케이션을 위한 데이터 모델 설계의 주요 결정 사항은 도큐먼트 구조와 애플리케이션이 데이터 간의 관계를 표현하는 방식을 중심으로 이루어집니다. MongoDB를 사용하면 관련 데이터를 단일 도큐먼트에 포함 할 수 있습니다. 실제로 많은 MongoDB의 사용 사례에서 비정규화 된 데이터 모델이 MongoDB에 최적임을 확인할 수 있는 사례가 많이 있습니다.
임베디드 데이터
임베디드 도큐먼트는 관계성이 있는 데이터들을 하나의 도큐먼트 구조에 저장할 수 있습니다. MongoDB 도큐먼트를 사용하면 도큐먼트 안에 필드 또는 배열을 도큐먼트 구조에 포함시킬 수 있습니다. 이렇게 비정규화 된 데이터 모델을 통해 애플리케이션이 한 번의 데이터베이스 작업으로 관련된 데이터들을 검색하고 처리 할 수 있습니다. 임베디드 데이터 모델을 사용하면 단일 원자 쓰기 작업으로 관련 데이터를 업데이트 할 수 있습니다.

일반적으로 다음과 같은 경우 임베디드 데이터 모델을 사용해야 합니다.
- 1:1 관계에서 엔티티 사이의 ‘포함’된 관계가 있는 경우.
연결된 데이터를 단일 도큐먼트에 포함하면 데이터를 얻는 데 필요한 읽기 작업 수를 줄일 수 있습니다. 일반적으로 애플리케이션이 단일 읽기 작업으로 필요한 모든 정보를 수신하도록 스키마를 구조화 해야합니다.
아래는 고객과 주소 관계를 매핑하는 예제입니다. 이 예제는 한 데이터 엔터티를 다른 데이터 엔터티에서 볼 필요가있는 경우, 참조보다 임베딩의 이점을 보여줍니다. 고객과 주소 데이터 사이의 일대일 관계에서 주소는 고객의 데이터 입니다.// 후원자 도큐먼트 { _id: "joe", name: "Joe Bookreader" } // 주소 도큐먼트 { patron_id: "joe", // 후원자 도큐먼트를 참조 street: "123 Fake Street", city: "Faketon", state: "MA", zip: "12345" }하나의 도큐먼트로 임베딩
{ _id: "joe", name: "Joe Bookreader", address: { street: "123 Fake Street", city: "Faketon", state: "MA", zip: "12345" } }
- 하위 도큐먼트가 항상 상위 도큐먼트와 함께 읽어져야 하는 1:N 관계
아래는 고객과 주소 관계를 매핑하는 예제입니다. 이 예제는 다른 컨텍스트에서 많은 데이터 항목을 볼 필요가있는 경우 참조보다 임베딩의 이점을 보여줍니다. 고객과 주소 데이터간의 일대다 관계에서 고객이 여러 주소 엔티티를 갖는 경우입니다.// 후원자 도큐먼트 { _id: "joe", name: "Joe Bookreader" } // 주소 도큐먼트 { patron_id: "joe", // 후원자 도큐먼트 참조 street: "123 Fake Street", city: "Faketon", state: "MA", zip: "12345" } { patron_id: "joe", street: "1 Some Other Street", city: "Boston", state: "MA", zip: "12345" }하나의 도큐먼트로 임베딩
{ "_id": "joe", "name": "Joe Bookreader", "addresses": [ { "street": "123 Fake Street", "city": "Faketon", "state": "MA", "zip": "12345" }, { "street": "1 Some Other Street", "city": "Boston", "state": "MA", "zip": "12345" } ] }
임베디드 도큐먼트 사용시, 하위 도큐먼트의 필드명이 길어지는 경우 데이터가 증가하기 때문에, 적절하게 줄여서 사용하는 것도 중요합니다. 조회되는 도큐먼트 양이 늘어난다면, 하위 도큐먼트가 가진 긴필드명 역시 몇 바이트가 모여 큰 데이터 사이즈를 가질수 있기 때문입니다.
참조(References)
참조는 한 도큐먼트에서 다른 도큐먼트로 링크 또는 참조를 포함하여 데이터 간의 관계를 저장합니다. 응용 프로그램은 이러한 참조를 확인하여 관련 데이터에 액세스 할 수 있습니다. 일반적으로 이들은 정규화 된 데이터 모델입니다.

참조의 경우 아래와 같은 경우 사용해야 합니다.
- 임베딩으로 인해 데이터가 중복되지만 중복의 의미를 능가 할만큼 충분한 읽기 성능 이점을 제공하지 못할 때
- 더 복잡한 다 대 다(N:N) 관계일 때
- 대규모 계층형 데이터 셋을 모델링 할 때
컬렉션 간의 조인은 MongoDB의 aggregation stage로 구현할 수 있습니다.
$lookup(3.2 이상)$graphLookup(3.4 이상)
MongoDB는 컬렉션간에 데이터를 결합하기위한 참조도 제공합니다.
다음 예제는 출판사와 도서의 관계를 매핑하는 예제입니다. 이 예제는 게시자 정보의 반복을 방지하기 위해 임베딩보다 참조하는 이점을 보여줍니다.
{
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher: {
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
{
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher: {
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
출판 데이터의 반복을 방지하려면 참조를 사용하여 출판 정보를 도서 컬렉션과 별도의 컬렉션으로 분리합니다.
참조를 사용할 때 관계의 증가에 따라 참조를 저장할 위치가 결정됩니다. 출판사당 도서 수가 적고 성장이 제한적인 경우, 출판 정보 도큐먼트 내에 도서 정보를 참조로 저장하는 것이 더 유용할 수 있습니다. 그렇지 않고 출판사당 도서 수가 제한되지 않은 경우 이 데이터 모델은 다음 예제와 같이 가변적이고 증가하는 배열로 구현합니다.
{
name: "O'Reilly Media",
founded: 1980,
location: "CA",
books: [123456789, 234567890, ...]
}
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English"
}
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English"
}
book 필드는 배열로 되어 있고, 배열에 도서 정보가 포함되어 있습니다. 하지만 배열의 증가를 피하고 데이터의 변경을 유용하게 하려면 반대로 도서 정보 도큐먼트에 출판사 도큐먼트를 참조 할 수 있습니다.
{
_id: "oreilly",
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "oreilly"
}
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher_id: "oreilly"
}
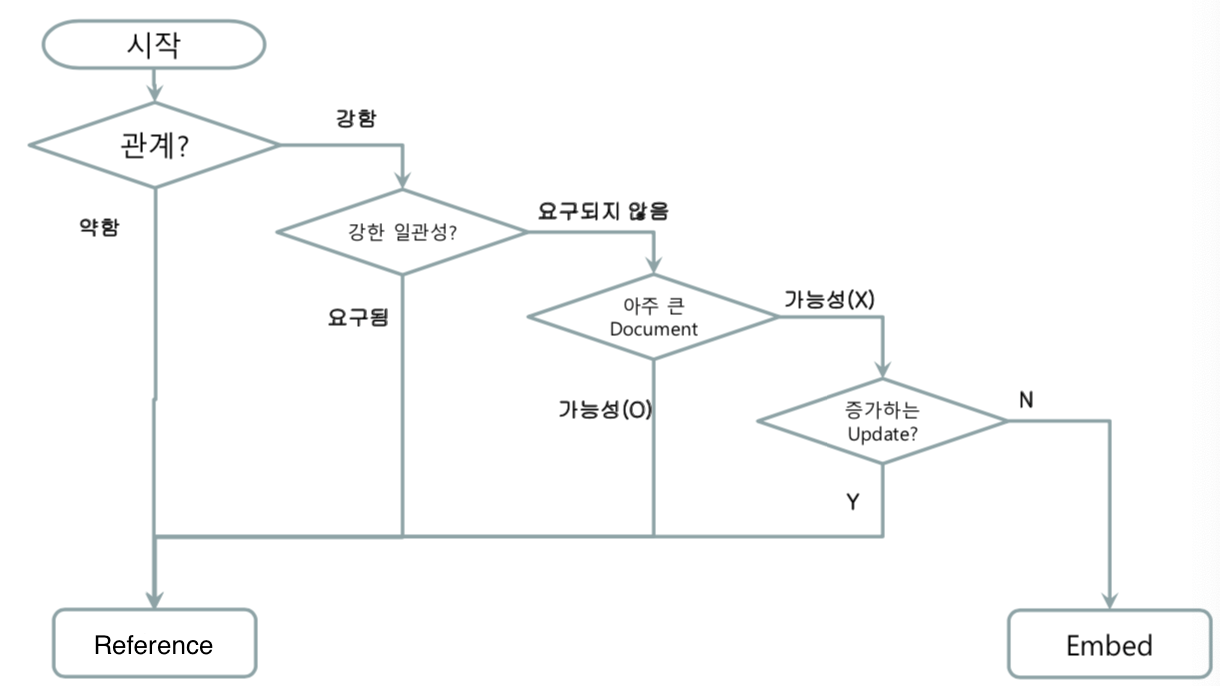
다음은 모델링 할때 임베딩 할 것인지, 참조를 할 것인지 고려할 때 참고할 만한 자료입니다.
| Embeded 가 좋은 경우 | Reference가 좋은 경우 |
| 작은 서브 도큐먼트 | 큰 서브 도큐먼트 |
| 주기적으로 변하지 않는 데이터 | 자주 변하는 데이터 |
| 결과적인 일관성이 허용될 때 | 즉각적인 일관성이 필요할 때 |
| 증가량이 적은 도큐먼트 | 증가량이 많은 도큐먼트 |
| 두 번째 쿼리를 수행하는데 자주 필요한 데이터 | 결과에서 자주 제외되는 데이터 |
| 빠른 읽기 | 빠른 쓰기 |
MongoDB의 View
MongoDB의 View는 다른 컬렉션 또는 View의 집계 파이프라인에 의해 컨텐츠가 정의 되는 쿼리 가능한 객체입니다. 일반적으로 RDBMS에서 View는 다음과 같은 경우 사용합니다.
- 복잡한 형태의 데이터 가공 조직을 캡슐화해서 사용자의 접근 용이성을 향상
- 테이블의 일부 데이터에 대해서만 접근 권한을 허용하여 보안 강화
MongoDB의 View는 아직 Materialized View는 제공하고 있지 않으며, view 자체를 따로 저장하지는 않고, 클라이언트가 보기를 원할 때 필요에 따라 계산되어 결과값이 보여집니다. MongoDB의 View에는 쓰기 작업은 지원되지 않습니다. 컬렉션과 동일하게 취급되여 show collections 명령으로 조회 할 수 있지만, 해당 명령으로는 어떤 것이 view 인지는 알 수 없습니다. view가 생성되면 view에 대한 메타정보는 system.view 컬렉션이 가지고 있기 때문에 db.systerm.views.find() 명령으로 조회할 수 있습니다. 그리고 view는 실제 데이터를 가지고 있지 않기 때문에 삭제한다고 하여 관련 컬렉션이 지워진다거나 데이터가 삭제되는 경우는 없습니다. 다음은 MongoDB에서 view를 사용할 때 주의 사항입니다.
- view는 항상 aggregate 처리되므로 조건에 일치하는 인덱스가 있어야 빠른 결과를 가져올수 있으며, 그렇지 않으면 풀스캔 하게 된다.
- 중첩된 view 역시 aggregate 쿼리가 실행 되는것과 동일하기 때문에 외부의 뷰쿼리는 인덱스가 없는 상태의 컬렉션에 대해 쿼리를 실행하는 것과 같아 처리해야 할 도큐먼트가 많으면 성능을 보장하기 어렵다.
- 별도를 저장하지 않기 때문에 무거운 데이터 가공작업이 많다면, 그만큼 성능이 떨어지게 된다.
MongoDB의 view가 aggregate 명령을 실행하는 것과 차이점을 보이는 것중 하나가 aggregate 명령에서 사용할 수 있는 모든 스테이지를 사용할 수 있는 것은 아닙니다. 따라서 어떤 스테이지가 지원되는지 확인을 거치고 생성을 해야합니다.
다음은 4.4 버전부터 view에 대한 변경 사항입니다.
- 4.4 버전부터 MongoDB의 veiw에서 $nutural 정렬을 지정할 수 있습니다.
- view는 aggregate 와 마찬가지로 100MB로 메모리 사용이 제한됩니다. MongoDB 4.4버전부터 view에서
allowDiskUse: true옵션을 사용하여find()명령에서 메모리를 대신해 임시 파일을 사용할 수 있습니다.
배열 (Array)
복잡한 형태의 모델링을 구현하는데 있어서 RDBMS에서 구현하지 못하는 기능중에 하나가 배열입니다. 실제로 배열을 사용하게 되면 여러 개의 컬렉션으로 분리돼야 할 데이터가 하나의 컬렉션에 모두 저장되므로 한 번의 쿼리로 조회하거나 변결할 수 있고, 컬렉션이 여러 개일 때보다 빠르게 개발이 가능해 집니다. 배열에도 멀티키 인덱스(Multi-key index) 생성을 통해 성능에 큰 제약은 없고, 3.2 버전 이상에서 배열내의 데이터가 증가 하더라도, 조회 및 데이터 쓰기, 변경 작업을 하더라도 성능 저하는 크게 발생하지 않습니다. 다만, 배열 값에 멀티 키 인덱스가 설정되어 있거나, 레플리카 셋에서 복제가 일어날때, 배열 필드는 필드 값과 다르게 변경된 값만 oplog에 전송되는 것이 아닌, 배열 전체를 전송하기 때문에 배열이 커진다면 복제 지연이 발생할 수도 있습니다. 따라서 배열의 크기가 커진다면 이상치 패턴을 이용하는 방법도 있습니다.
이상치 패턴을 사용하면 배열의 요소가 특정 갯수를 기준으로 새 도큐먼트로 분할하면 됩니다.
아래는 팔로워 리스트에 대한 모델링으로 특정 유저의 팔로워 목록이 배열로 저장되어 있습니다.
{
"_id" : ObjectId("6062c5c009fab8547ddb977e"),
"userId" : ObjectId("6062c5c009fab8547ddb977d"),
"username" : "judy",
"count" : 512,
"followers" : [
ObjectId("6062c6b309fab8547ddb9787"),
ObjectId("6062c6db09fab8547ddb978c"),
ObjectId("6062c65909fab8547ddb9782"),
ObjectId("6062c80709fab8547ddb979b"),
ObjectId("6062c7c309fab8547ddb9796"),
ObjectId("6062c73609fab8547ddb9791"),
ObjectId("6062c86b09fab8547ddb97a0"),
ObjectId("6062c8bb09fab8547ddb97a5"),
...
...
...
]
}
배열의 엘리먼트로 ObjectId를 저장하는 경우 ObjectId 하나에 12byte로 도큐먼트 최대 크기인 16MB까지 채운다면 거의 400백만개가 넘게 들어갑니다. 하지만 위에서 언급했듯이 이런 경우 복제 지연이 발생할 수 있기 때문에 문제가 될 수 있습니다.
이상치 패턴을 적용하면 다음과 같이 변경할 수 있습니다.
{
"_id" : ObjectId("6062c5c009fab8547ddb977e"),
"userId" : ObjectId("6062c5c009fab8547ddb977d"),
"username" : "judy",
"count" : 200,
"addList" : [ ObjectId("6062c5c009fab8547ddb977f"),ObjectId("6062c5c009fab8547ddb977g") ],
"followers" : [
ObjectId("6062c6b309fab8547ddb9787"),
ObjectId("6062c6db09fab8547ddb978c"),
ObjectId("6062c65909fab8547ddb9782"),
ObjectId("6062c80709fab8547ddb979b"),
ObjectId("6062c7c309fab8547ddb9796"),
ObjectId("6062c73609fab8547ddb9791"),
ObjectId("6062c86b09fab8547ddb97a0"),
ObjectId("6062c8bb09fab8547ddb97a5"),
ObjectId("6062c8bb09fab8547ddb97a6"),
ObjectId("6062c8bb09fab8547ddb97a7"),
...
...
...
]
}
{
"_id" : ObjectId("6062c5c009fab8547ddb977f"),
"count" : 200,
"followers" : [
ObjectId("6062c6b309fab8547ddb9788"),
ObjectId("6062c6db09fab8547ddb9789"),
ObjectId("6062c65909fab8547ddb9780"),
ObjectId("6062c80709fab8547ddb979c"),
ObjectId("6062c7c309fab8547ddb9797"),
ObjectId("6062c73609fab8547ddb9792"),
ObjectId("6062c86b09fab8547ddb97a1"),
ObjectId("6062c8bb09fab8547ddb97a6"),
ObjectId("6062c8bb09fab8547ddb97a7"),
ObjectId("6062c8bb09fab8547ddb97a8"),
...
...
...
]
}
{
"_id" : ObjectId("6062c5c009fab8547ddb977g"),
"count" : 112,
"folloewers" : [
ObjectId("6062c6b309fab8547ddb971a"),
...
...
...
ObjectId("6062c6db09fab8547ddb9712")
]
}
기존의 followers 도큐먼트에 addList 라는 필드를 추가해 팔로워를 나타내는 배열 타입의 데이터와 카운트 정보만 담긴 도큐먼트의 _id 값을 추가해 줍니다.
특정 기준을 가지고 배열을 여러 도큐먼트에 분산하여 배열 안에 엘리먼트가 증가해도 성능이 보장되는 시점까지 저장하여 도큐먼트의 수를 줄여 도큐먼트에 대한 크기와 읽기 성능을 해결할 수 있습니다. 팔로워 리스트의 경우 애플리케이션 단에서 한번에 가져오는것이 아니라 슬라이싱된 기준에 의해 특정 화면으로 넘어갔을때 추가적인 로딩이 필요하게 설계가 되기 때문에 한번에 모든 도큐먼트가 아닌 순차적인 로딩을 통해 읽기 성능을 올릴수도 있습니다.
MongoDB의 다양한 모델링 패턴
MongoDB는 blog를 통해 성능에 최적화 할 수 있는 다양한 모델링 패턴을 소개합니다.
- The Polymorphic pattern (다형성 패턴): 컬렉션 내 모든 도큐먼트가 유사하지만 동일하지 않은 구조를 가질때 적합.
- The Attribute pattern (속성 패턴): 정렬하거나 쿼리하려는 공통 특성을 갖는 도큐먼트에 필드의 서브셋이 있는 경우, 정렬하려는 필드가 도큐먼트에 서브셋에만 있는 경우 또는 두 조건이 모두해당하느 경우에 적합
- The Bucket pattern (버킷 패턴): 데이터가 일정 기간 동안 스 트림으로 유입되는 시계열 데이터에 적합
- The Outlier pattern (이상치 패턴): 도큐먼트의 쿼리가 애플리케이션의 정상적인 패턴을 벗어 날 때 적합. 인기도가 중요한 상황을 위해 설계
- The Computed pattern (계산된 패턴): 데이터를 자주 계산해야 할 때나 데이터 접근 패턴이 일기 집약적 일때 적합. 동일 계산의 반복을 줄이고, 계산없이 근사치를 제공
- The Subset pattern (서브셋 패턴): 장비의 램 용량을 초과하는 작업 셋이 있을때 적합
- The Extended Reference pattern (확장된 참조 패턴): 각각의 고유한 컬렉션이 있는 여러 논리 엔티티 또는 사물이 있고, 특정 기능을 위해 엔티티들을 모을때 사용
- The Approximation pattern (근사 패턴): 리소스가 많이 드는 (시간, 메모리, CPU사이클) 계산이 필요하지만, 정확도가 반드시 필요하지는 않는 상황에 적합
- The Tree pattern (트리 패턴): 쿼리가 많고 구조적으로 주로 계층적인 데이터가 있을때 적용. 일반적으로 쿼리되는 데이터를 한데 저장하는 방식을 따름.
- The Preallocation pattern (사전 할당 패턴): 빈 구조를 사전에 할당
- The Document Versioning Pattern (도큐먼트 버전 관리 패턴): 도큐먼트의 이전 버전을 유지하는 매커니즘을 제공
도큐먼트 유효성 체크 (Schema Validation)
도큐먼트 유효성 체크는 MongoDB 3.2 이상의 버전부터 지원하는 기능입니다. MongoDB는 스키마 프리(schema-free)의 특징을 지니고 있고 동일 컬렉션 내에서도 언제든 원하는 필드를 추가하거나 삭제한 도큐먼트를 추가 할 수 있습니다.
하지만 실수에 의한 필드가 추가되거나 무의미한 도큐먼트의 변형을 방지하기 위해 유효성 체크를 지정할 수 있습니다.
아래는 블로그 포스트에 대한 likes 통계를 위해 따로 빼둔 like 컬렉션에 대한 유효성이 지정된 컬렉션을 만드는 예제입니다.
db.createCollection("likes", {
"storageEngine": {
"wiredTiger": {}
},
"capped": false,
"validator": {
"$jsonSchema": {
"bsonType": "object",
"title": "likes",
"properties": {
"_id": {
"bsonType": "objectId"
},
"postId": {
"bsonType": "objectId",
"description": "포스트 ID"
},
"count": {
"bsonType": "number",
"description": "포스트 Like 수",
"minimum": 0
},
"likeUsers": {
"bsonType": "array",
"description": "like 누른 유저 목록 배열",
"additionalItems": true,
"items": {
"bsonType": "objectId",
"description": " 오브젝트ID"
}
}
},
"additionalProperties": false,
"required": [
"postId",
"count",
"likeUsers"
]
}
},
"validationLevel": "moderate",
"validationAction": "error"
});
이처럼 타입을 필드에 대한 값의 데이터 타입을 지정 할 수 있고, 마지막에 붙은 validationLevel과 validationAction의 값이 moderate와 error 이기 때문에 해당 필드에 적절하지 못한 데이터 타입이 들어온다면 error 메시지를 반환하며 데이터가 들어가지 않습니다. 또 배열의 갯수를 제한한다거나, Geojson을 사용하는 경우 validation을 통해 위경도의 범위를 제한 할 수 있습니다. boolean 타입을 사용한다면 필드값을 true와 false로 제한 할 수도 있습니다.
사용할 수 있는 옵션은 다음과 같습니다.
- validationLevel:
off – 사용하지 않는다.
strict – validationLevel의 기본값이며, insert나 update로 변경되는 모든 도큐먼트에 대해 유효성 체크를 한다.
moderate – insert와 유효성 체크를 만족하는 도큐먼트의 update에 대해서만 유효성 체크를 하고, 유효성 체크를 만족하지 못했던 도큐먼트에 대해서는 별도의 조치를 하지 않고 무시한다. - validationAction:
warn – validationLevel에 따라 튜효성 체크가 실패해도 경고만 반환하고 실제 insert나 update가 행해진다.
error – validationLevel에 따라 유효성 체크가 실패한 경우 error를 반환하며 아무런 작업도 하지 않는다.
참고 자료
도서: Real MongoDB
MongoDB Manual: https://docs.mongodb.com/manual/
최신 댓글