
MongoDB Transaction Management

MongoDB Transaction Management
MongoDB의 트랜잭션
MongoDB 4.0이 릴리즈 되면서 Replica Set에서 작동하는 다중 도큐먼트 트랜잭션에 대한 지원을 추가되었습니다. 또, MongoDB 4.2의 릴리스와 함께 다중 도큐먼트 트랜잭션에 대한 지원이 Sharded Cluster로 확장되었습니다.
현재의 MongoDB는 WiredTiger 스토리지 엔진을 사용하는데, WiredTiger 스토리지 엔진 자체가 NoSQL을 위한 엔진이 아니었습니다. 그래서 RDBMS의 특성을 많이 보여주며, RDBMS와 비슷한 ACID를 제공합니다. 하지만 MongoDB는 NoSQL 데이터베이스이며, 항상 단일 도큐먼트에 필요한 만큼의 데이터를 저장하도록 장려한다는 점에서 SQL 데이터 모델링과는 근본적으로 다릅니다. MongoDB의 특성을 알고 MongoDB에 맞게 사용하면 성능이 더 좋아지는 점을 기억하며, 관계형 데이터베이스처럼 사용하는 것을 피하는 것이 좋습니다.
MongoDB는 단일 문서에서 ACID 트랜잭션을 지원하므로 애플리케이션 개발자는 여러 문서에서 ACID 보장에 대해 걱정할 필요가 없습니다. 그러나 때로는 응용 프로그램의 요구 사항과 디자인에 따라 하나의 문서에 모든 것을 포함 할 수 없습니다. 도큐먼트가 여러 컬렉션에 분산되기를 원할 수 있으며 이러한 시나리오에서는 ACID 보장이 필요합니다.
WiredTiger 스토리지 엔진이 제공하는 트랜잭션의 ACID (Atomicity, Consistency, Isolation, Durability) 속성은 아래와 같은 특성이 있습니다.
- 최고 레벨의 격리 수준은 Snapshot (Repeatable-read)
- 트랜잭션의 Commit과 Checkpoint 2가지 형태로 영속성(Durability)을 보장
- Commit되지 않은 변경 데이터는 공유 캐시크기보다 작아야 함
일반적인 RDBMS에서는 READ-UNCOMMITED, READ-COMMITED, REPEATABLE-READ와 SERIALIZABLE, 총 4가지 격리 수준을 제공합니다. WiredTiger 스토리지 엔진은 SERIALIZABLE은 지원하지 않으며, READ-UNCOMMITED, READ-COMMITED의 격리 수준을 제공하긴 하지만 실제 선택하여 사용할 수는 없습니다. MongoDB 서버에서 격리 수준을 SNAPSHOT으로 고정해서 초기화 하기 때문입니다.
쓰기 충돌 (Write Conflict)
트랜잭션 범위 밖에있는 동일한 도큐먼트에서 동시에 여러 쓰기 작업을 수행하면 쓰기 충돌(WriteConflict)가 발생합니다. 그러나 쓰기 충돌이 발생하지 않는 시점 또는 사전에 정의된 시점까지 WiredTiger 스토리지 엔진이 WriteConfilct 오류를 내부적으로 처리하고 지속적으로 업데이트를 재시도하기 때문에 이 문제에 대해 걱정할 필요가 없습니다.
WriteConflict는 여러 사용자가 동시에 동일한 문서를 업데이트하려고 할 때를 나타냅니다. MongoDB는 WiredTiger 스토리지 엔진을 사용하여 이러한 문제를 처리합니다. 0이 아닌 WriteConflict는 도큐먼트에 대한 업데이트 요청이 데이터 동시성 위반을 일으킬 수 있음을 엔진에 알립니다. WiredTiger API가 동시성 위반으로 인해 WriteConflict를 감지할 때마다 WriteConflict 지표를 증가시키고 MongoDB는 충돌없이 완료 될 때까지 내부적으로 업데이트를 재시도합니다. WriteConflict의 수가 많으면 응용 프로그램 응답이 지연될 수 있으며 그 원인을 찾아야 합니다.
일반적으로 RDBMS에서는 두 개의 세션이 하나의 레코드에 변경 작업이 발생하는 경우 아래와 같이 동작합니다.
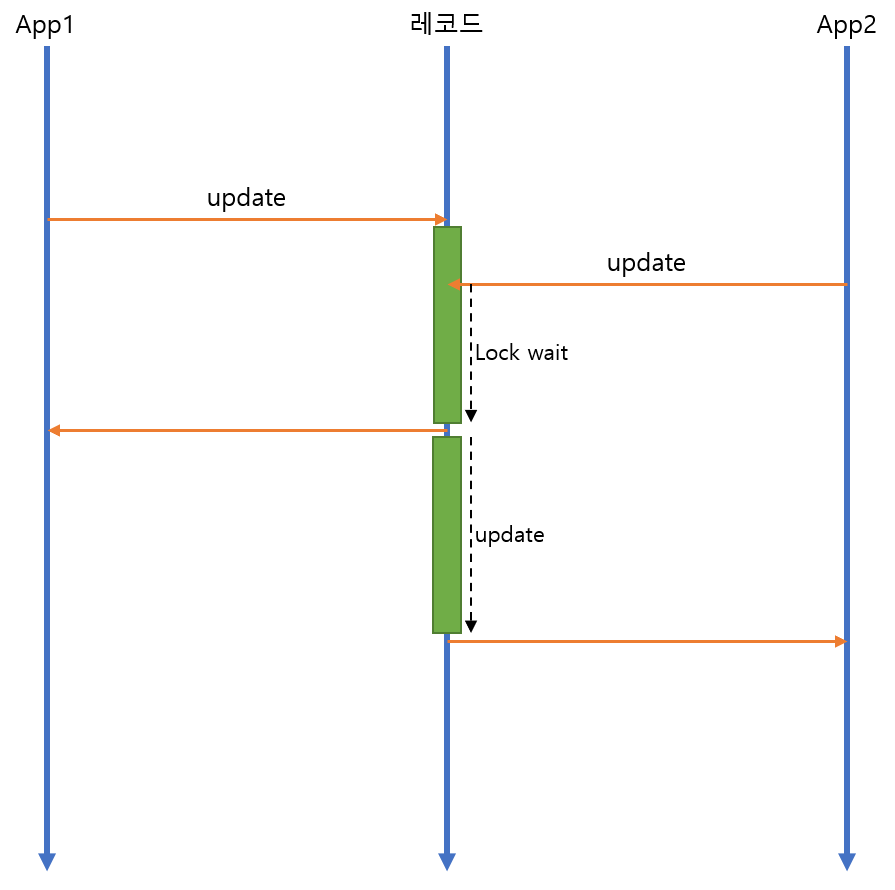
RDBMS에서 같은 레코드를 변경하기 위한 경합
먼저 들어온 세션이 먼저 업데이트를 진행하고, 업데이트를 진행하는 동안 두번째 세션은 명령자체를 취소하지 않고 Lock wait 에 걸려 있다가, 1번 세션의 작업이 끝난 후에 순차적으로 진행됩니다.
반면 MongoDB의 경합과정은 조금 다릅니다.
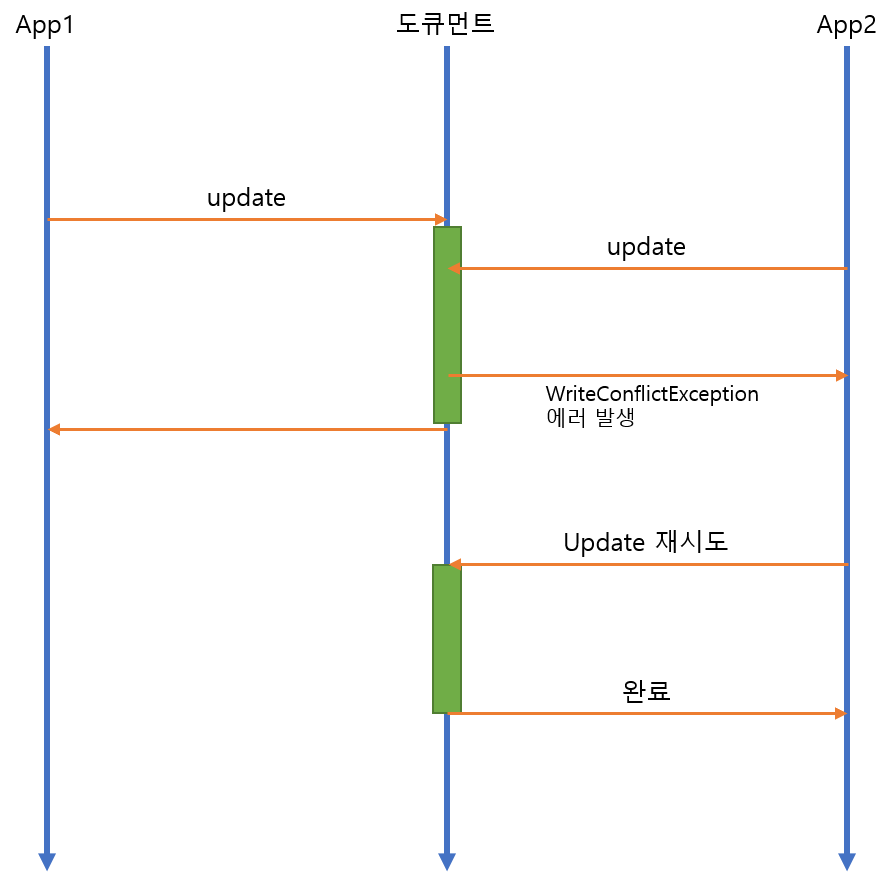
MongoDB에서 같은 도큐먼트 변경을 위한 경합
MongoDB는 변경하고자 하는 도큐먼트가 이미 다른 커넥션에 의해 Lock에 걸린 상태라면, 즉시 업데이트 명령을 취소합니다. 이때 스토리지 엔진은 WriteConflictException이라는 에러를 반환합니다. 이러한 경우 업데이트를 실행했던 세션은 WriteConflictException을 받고 같은 업데이트 명령을 재시도합니다. 이러한 과정은 MongoDB 서버 프로세스 내부에서만 실행되며, 애플리케이션 단에서는 이런 재시도가 있었는지 알 수 없습니다.
아래는 WriteConflict이 발생했을때의 예시입니다.
coll_name.update( { _id: 2 },{ $set: { a: 7 } });
WriteCommandError({
"errorLabels" : [
"TransientTransactionError"
],
"operationTime" : Timestamp(1566906756, 1),
"ok" : 0,
"errmsg" : "WriteConflict",
"code" : 112,
"codeName" : "WriteConflict",
"$clusterTime" : {
"clusterTime" : Timestamp(1566906756, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
})
WriteConflict가 지속적으로 발생하여 재처리 과정이 늘어나면 CPU의 사용량이 높아지며, WiredTiger 스토리지 캐시에 직접적인 부담을 주기 때문에 사용자 요청을 처리하는 성능이 떨어집니다. WriteConflictException가 얼마나 발생하는지는 db.serverStatus()명령으로 확인할 수 있으며, WriteConflictException가 자주 발생한다면 컬렉션 모델을 수정하여 WriteConflictException 발생을 최소화 하는 편이 좋습니다.
단일 도큐먼트 트랜잭션 (Single Document Transaction) 과 다중 도큐먼트 트랜잭션 (Multi Document Transaction)
앞에서 4.0 버전이 릴리즈 되면서부터 다중 도큐먼트 트랜잭션에 대한 지원이 가능해졌다고 설명했습니다. MongoDB는 4.0 이전 버전까지는 단일 도큐먼트의 트랜잭션만 지원을 했습니다.
단일 도큐먼트 트랜잭션이란 단일 도큐먼트의 변경에 대해서는 원자 단위의 처리가 보장된다는 것을 의미합니다. RDBMS의 데이터 모델에서는 서로 관계가 있는 데이터들을 정규화하여 서로 다른 테이블에 저장하지만, MongoDB의 도큐먼트 데이터 모델에서는 정규화를 하지 않고 한번에 로딩되어야 하는 데이터들은 하나의 도큐먼트에 넣는 것이 유리하기 때문에, MongoDB가 추구하는 방향에 따라 데이터 모델링을 한다면 단일 도큐먼트 트랜잭션만으로도 충분히 데이터의 정합성이 보장되었습니다. 하지만 항상 조건에 맞는 상황만 있는것이 아니기 때문에, 이전 버전에서 다중 도큐먼트 트랜잭션을 구형하기 위해서 애플리케이션 단에서 2-Phase-Commits 같은 방법을 이용해 개발단에서 구현을 해야 했습니다. 하지만 4.0 버전부터는 MongoDB 자체가 다중 도큐먼트 트랜잭션을 지원하기 시작했고, 4.2 버전부터는 단일 노드가 아닌 샤드 클러스터에 대해 다중 도큐먼트 트랜잭션을 구현합니다.
MongoDB의 기본 트랜잭션 제한은 60 초이며 제한을 벗어나 실행되는 모든 트랜잭션은 중단됩니다. 이 설정 값을 변경하여 더 오랜 시간 동안 트랜잭션을 실행 할 수 있습니다. 하지만 장시간 실행되는 트랜잭션은 WiredTIger 스토리지 엔진 캐시에 부담을 준다고 설명했습니다. 시간 초과 문제를 방지하려면 트랜잭션을 더 작은 부분으로 나누면서 DB 작업 만 수행해야합니다.
여러 샤드에 영향을 미치는 트랜잭션은 쿼리가 네트워크를 통해 여러 참여 노드에 브로드 캐스트되므로 성능 비용이 더 많이 발생합니다. 쿼리를 식별하고 적절한 인덱싱을 제공합니다. 분산 다중 샤드에서 일관된 읽기를 원하면 readConcern “Snapshot”을 사용해야 합니다. 이를 통해 여러 샤드에서 일관된 데이터 스냅 샷을 제공받을수 있습니다. 지연 시간이 애플리케이션의 문제인 경우 readConcern 레벨 “local”을 사용하는 것이 좋습니다.
다중 도큐먼트 트랜잭션을 지원하는 CRUD 동작들입니다.
Method |
Command |
Note |
|---|---|---|
다음 쿼리 연산자 표현식 제외 : 이 메서드는 쿼리에 |
||
샤딩되지 않은 컬렉션에서만 사용할 수 있습니다. |
||
4.4 버전 이상의 경우, update 또는 replace 동작을 |
||
4.4 버전 이상의 경우, 존재하지 않는 컬렉션을 즉시 생성합니다. |
||
4.4 버전 이상의 경우, 존재하지 않는 컬렉션에 대한 insert 작업은 컬렉션을 즉시 생성합니다. |
||
4.4 이상의 버전에서 |
||
4.4 이상의 버전에서 insert와 update 작업에 |
MongoDB의 격리수준
MongoDB의 WiredTiger 스토리지 엔진은 SNAPSHOT 격리 수준만을 지원한다고 위에서 설명했습니다. SNAPSHOT 격리 수준에서는 하나의 트랜잭션 내에서 하나의 쿼리는 항상 같은 결과를 반환해야 합니다. 첫번째 세션에서 트랜잭션이 발생한 동안 두번째 세션에서 업데이트가 이루어진 경우에, 트랜잭션이 끝나지 않은 첫번째 세션에서는, 두번째 세션에서 값이 업데이트가 되었음에도 불구하고, 트랜잭션이 끝나기 전까지는 트랜잭션을 시작했을 때의 값을 보여주는 것을 의미합니다.
MongoDB의 데이터 변경은 하나의 도큐먼트를 변경할 때마다 내부적으로 트랜잭션이 커밋되기 때문에, 배치 작업으로 실행되는 업데이트나 삭제 작업에도 내부적으로는 개별 트랜잭션으로 처리되어 처리하는 도중에 장애가 발생하여 멈추게 되더라도, 앞에 처리해버린 도큐먼트들은 롤백을 할 수 없습니다. 이러한 트랜잭션 구조 때문에 대량의 변경 작업이 있어도 실제 도큐머트당 발생하는 트랜잭션의 유지 시간이 짧기 때문에, RDBMS 처럼 대량의 변경작업으로 인한 트랜잭션 유지에 의한 성능저하는 거의 발생하지 않습니다.
반면에 읽기 쿼리는 도큐먼트 한 건을 읽을때마다 트랜잭션을 발생하는 구조가 아니며 일정 단위로 트랜잭션을 시작하고 완료합니다. 모든 도큐먼트를 읽기 작업을 할 때 트랜잭션을 시작하고 완료하게 되면 성능저하가 발생하기 때문에 읽기 트랜잭션은 쓰기와 다른 방식으로 동작한다는 사실을 알아두셔야 합니다.
Read & Write Concern, Read Preference
대부분의 RDBMS는 단일 노드로 작동하는 아키텍처를 기본으로 하고 있습니다. 반면 MongoDB는 분산 처리를 기본 아키텍처로 선택하고 있기 때문에 레플리카 셋을 구성하는 멤버들 간의 동기화 역시 제어할 수 있습니다. 필요한 데이터의 동기화 (ACID의 Durability 속성) 수준에 따라 데이터를 변경 할 수 있도록 Read Concern과 Write Concern 옵션을 제공합니다. RDBMS에서는 디스크의 동기화 처리를 일괄적으로 설정하지만, MongoDB에서는 클라이언트 프로그램에서 쿼리 단위로 다르게 설정할 수가 있습니다.
Read Concern에 대한 내용은 이전에 읽기 연산에 대한 포스팅에서 설명을 한적이 있습니다.
Read Concern
MongoDB의 서버는 분산 처리구조로 되어 있기 때문에 여러 레플리카 멤버중에서 어떤 멤버를 선택하느냐에 따라 FIND 결과가 달라질 수도 있습니다. MongoDB의 복제는 비동기 모드이며, 최종 일관성(Eventual Consistency) 모델을 채택하고 있기 때문입니다. 하지만 데이터를 읽어가는 쿼리 입장에서는 “Eventual Consistency”가 수많은 문제점을 유발할 가능성이 있습니다. 이런 동기화 과정중에 데이터 읽기를 일관성 있게 유지할 수 있도록 ReadConcern 옵션을 제공합니다. ReadConcern 옵션은 WriteConcern 옵션과 달리 레플리카 셋 간의 동기화 이슈만 제어합니다.
ReadConcern 옵션은 4.4 버전 이상의 버전에서 다섯가지를 가지고 있습니다.
- local: MongoDB의 기본 ReadConcern옵션인데, local 모드에서는 다른 멤버가 가진 데이터의 상태를 확인하지 않기 때문에 최신의 데이터를 프라이머리 멤버만 가진 상태에서 프라이머리 멤버가 비정상적으로 종료되거나 연결이 끊어지면 그 데이터는 롤백 되서 Phantom Read와 비슷한 상황이 발생할 수도 있습니다. causally consistent session 또는 트랜잭션에서 사용할 수 있습니다.
- available: 과반수에 기록되었음을 확인하지 않고 데이터를 반환합니다. 읽어온 데이터가 롤백될수 있습니다. causally consistent session 또는 트랜잭션에서 사용할 수 없습니다.
- majority: 레플리카 셋에서 다수의 멤버들이 최신의 데이터를 가졌을 때에만 읽기 결과가 반환됩니다. 이를 충족하기 위해 각 레플리카 셋 멤버들이 메모리의 majority-commit point 반환해야 합니다. 따라서 위 두 설정에 비해 성능이 떨어집니다. causally consistent session 또는 트랜잭션에서 사용할 수 있습니다. PSA 아키텍처를 사용할 때 이 설정을 쓰지 않게 설정할 수 있습니다. 하지만 이것은 Change Streams, 트랜잭션, 샤디드 클러스터에 영향을 줄 수 있습니다. 자세한 내용은 Disable Read Concern Majority에서 확인하시길 바랍니다.
- linearizable: 모든 레플리카 셋의 멤버들이 데이터를 반영하고 있을때 결과를 반환합니다. 프라이머리 스위칭이 일어나도 데이터가 롤백 될 일이 없으며, Phantom Read가 전혀 발생하지 않습니다. causally consistent session 또는 트랜잭션에서 사용할 수 없습니다.
프라이머리 노드에만 설정할 수 있습니다. 어그리게이션의 $out, $merge 스테이지에서 사용할 수 없습니다. 유니크하게 식별가능한 단일 도큐먼트에 읽기 작업에서만 보장됩니다. - snapshot: 트랜잭션이 causally consistent session 이 아니고 Write concern 이 majority 인 경우, 트랜잭션은 과반이 커밋된 데이터의 스냅샷에서 읽습니다. 트랜잭션이 causally consistent session 이고 Write concern 이 majority 인 경우, 트랜잭션 시작 직전에 과반이 커밋된 데이터의 스냅샷에서 읽습니다. 멀티 도큐먼트 트랜잭션에서만 사용가능합니다. 샤딩된 클러스터 중 하나라도 Disable Read Concern Majority 설정을 할 경우 사용할 수 없습니다.
majority 모드의 ReadConcern을 사용하려면 반드시 MongoDB 설정에 enableMajorityReadConcern 옵션이 활성화 되어 있어야 합니다.
$ mongod -- enableMajorityReadConcern or setParameter: enableMajorityReadConcern: true
MongoDB에서 ReadConcern 모드로 쿼리를 실행하면 오직 레플리카 셋의 OpLog 동기화 여부에만 의존해서 쿼리의 ReadConcern을 처리합니다. 프라이머리 멤버는 모든 세컨더리 멤버들이 OpLog의 어느 부분까지 동기화하고 있는지 정보를 가지고 있으며, 각 세컨더리 멤버는 프라이머리 멤버의 OpLog를 조회할 때 마다 자신이 얼마나 동기화 했는지를 프라이머리 멤버에 보고하는 방식으로 동작합니다. 프라이머리 멤버는 클라이언트의 쿼리 요청이 오면 자신이 가진 세컨더리 멤버들의 OpLog 상태 정보를 참고하여설정 값에 따른 멤버들이 현재 자신의 OpLog와 동일한지 확인 후 쿼리를 처리 합니다. 설정 값에 따라 멤버들이 프라이머리의 OpLog와 동일한 상태가 아니라면 쿼리를 멈추고, 세컨더리 멤버들을 원하는 수준까지 동기화될 때까지 기다립니다. ReadConcern을 사용할 때에는 “local”이 아닌 경우에는 반드시 maxTimeMS 옵션을 설정하기를 권장하고 있습니다.
ReadConcern 옵션은 클라이언트와 데이터베이스, 그리고 컬렉션 레벨의 3가지 방법으로 설정할 수 있습니다.
Write Concern
이전 버전의 MongoDB에서는 RDBMS와는 달리 트랜잭션의 시작과 종료(Commit)을 명시적으로 실행할 방법이 없기 때문에 도큐먼트를 저장할 때 사용자의 데이터 변경 요청에 응답일 반환하는 시점이 트랜잭션의 커밋으로 간주됩니다. 변경 요청에 대한 응답 시점을 결정하는 옵션을 WriteConcern이라고 합니다. WriteConcern은 Insert, update, delete 작업에서만 설정이 가능합니다. WriteConcern 옵션 역시 클라이언트와 데이터베이스, 그리고 컬렉션 레벨의 3가지 방법으로 설정할 수 있습니다.
단일 노드의 동기화 제어 방법은 변경된 데이터가 디스크에 동기화 되었는가에 따라 언제 완료메시지를 보낼것인지 판단하는 기준이 됩니다. 단일 노드 동기화 제어 옵션으로는 UNACKNOWLEDGED, ACKNOWLEDGED, JOURNALED 옵션 세가지가 있습니다. UNACKNOWLEDGED는 현재 버전에서는 잘 사용하지 않고 ACKNOWLEDGED가 기본값으로 사용되어 집니다. ACKNOWLEDGED는 변경값은 메모리에만 적용하고, 바로 클라이언트에 성공 또는 실패 응답을 전달합니다. 실제로 다른 커넥션에서 조회를 하면 변경된 값으로 조회가 되면 변경값이 실제 반영된것 처럼 보입니다. 하지만 디스크에도 변경된 내용이 기록되었는지에 대해서는 보장하지 않습니다. 메모리상에 변경 적용된 데이터가 디스크에 기록되기전에 장애가 발생한다면 데이터 손실의 위험이 있습니다.
MongoDB 2.6 부터 저널로그가 도입 되었는데, 저널 로그는 클라이언트가 변경한 데이터를 RDBMS의 트랜잭션 로그 처럼 디스크로 먼저 동기화 하여 서버의 비정상적인 종료로부터 데이터 손실을 방지합니다. 즉 데이터파일에 기록하기전에 저널로그에 먼저 기록해두는 것인데 ACKNOWLEDGED 모드의 WriteConcern이 서비스 요건으로 만족하지 못할때 JOURNALED 옵션을 고려할 수 있습니다. 하지만 JOURNALED 옵션이 최상의 일관성 옵션을 보장해주는 것은 아닙니다. 단일 노드는 디스크 동기화만 신경쓰면 되지만, 레플리카 셋에서는 세컨더리 멤버들의 디스크 동기화까지 고려를 해야합니다.
그래서 MongoDB에는 레플리카 셋 전체에 걸쳐 동작하는 WriteConcern 모드가 있습니다. 리플리카 셋의 여러 노드에 대해 WriteConcern를 설정하는 방법은{ w: <?> } 옵션을 사용하면 됩니다.
- 숫자값: 이 값은 레플리카 셋에서 데이터를 동기화 해야하는 멤버의 수를 나타내는데, 프라이머리를 포함한 숫자이기 때문에 2로 설정을 하면 프라이머리 1대와 세컨더리 1대가 변경요청을 필요한 수준까지 처리를 해야 성공 또는 실패 메시지를 반환하게 됩니다. 2는 WriteConcern 모드의 기본값입니다. 물론 1로 놓고 써도 저널로그를 통해 롤백이 가능하기 때문에 수동으로 복구가 가능한 환경이라면
j:true, w:1로 놓고, 프라이머리에 저널로그가 기록되면 반환하는 옵션을 사용하기도 합니다. - majority: 과반수의 멤버가 동기화 되는 옵션인데, 레플리카 셋의 멤버의 수가 자주 변화는 환경이라면, 멤버수가 바뀔때 숫자값을 설정하면 매번 수동으로 바꿔줘야 하지만, majority는 옵션값을 유지한채로 사용이 가능해집니다.
Read Preference
Secondary 노드들이 동기화한 데이터를 예비 Primary를 위한 후보군으로만 사용하는 것이 아니라 Read 작업을 분산할 수 있도록 설정해주는 것입니다.
읽기 작업의 분산을 통해 Primary에 들어오는 부하를 줄일 수 있습니다.

read Preference
기본값일때는 모든 작업이 Primary에서 동작합니다. 하지만 readPreference 설정을 하게 되면 읽기 작업을 Secondary에서 할 수 있습니다.
4.4 버전부터는 샤드 클러스터에 대한 hedged read를 지원합니다. hedged read를 사용하면 mongos 인스턴스는 쿼리 된 각 샤드 당 2 개의 복제본 세트 구성원으로 읽기 작업을 라우팅하고 샤드 당 첫 번째 응답자의 결과를 반환 할 수 있습니다.
nearest 옵션을 사용하면, 해당 구성원이 Primary인지 Secondary인지에 관계없이 네트워크 대기 시간이 가장 짧은 복제본 세트의 구성원에서 읽기 작업을 합니다.
readPreference 설정은 실제로 클라이언트의 드라이버에서 설정을 하는 것이기 때문에 개발 환경마다 설정하는 방법이 조금씩 다를수 있습니다. 각 개발 언어별로 설정하는 법은 MongoDB API 문서(https://docs.mongodb.com/drivers/)에서 확인하시면 됩니다.
아래는 node.js에서 mongoose 모듈을 이용해 설정하는 방법입니다. (예제 출처: 맛있는 몽고DB 7장 복제)
var opts = {
replSet: {readPreference: 'ReadPreference.NEAREST'}
};
mongoose.connect('mongodb://<연결 주소> ', opts);
커서나 컬렉션을 불러올때 readPreference 옵션을 사용하여 읽기 분산을 처리할 수 있습니다.
MongoDB의 공식 문서에 따르면 readPreference 옵션은 5가지가 있습니다.
- primary: 기본값이며, Primary 구성원으로부터 값을 읽고 오며, 딜레이 없이 데이터 수정 및 삽입 작업이 가능합니다.
- primaryPreferred: Primary 구성원으로부터 우선적으로 데이터를 읽어옵니다. 특별히 Primary 쪽의 읽기 작업이 밀려있지 않으면 Primaey에서 데이터를 가져오기 때문에 변경사항을 바로 확인 할 수 있습니다. 읽기가 밀려 있는 상태라면 Secondary에서 데이터를 읽어옵니다.
- secondary: 모든 읽기 작업을 Secondary 에서 처리합니다.
- secondaryPreferred: 우선적으로 읽기 작업이 발생하면 Secondary에 작업을 요청합니다. 하지만 모든 Secondary에서 작업이 밀려 있는 경우 Primary에 읽기 작업을 요청합니다.
- nearest: 해당 구성원이 Primary인지 Secondary인지에 관계없이 네트워크 대기 시간이 가장 짧은 복제본 세트의 구성원에서 읽기 작업을 합니다.
MongoDB의 복제는 비동기 방식으로 처리되므로 세컨더리 멤버를 통해 무거운 쿼리를 많이 돌게 되면 복제 지연이 발생할 수도 있습니다. 하지만 복제 지연에 민감하지 않거나, 복잡한 연산으로 프라이머리에 부하를 많이 줄수 있는 통계작업이 있다면 세컨더리 노드를 활용하는 것도 좋은 방법입니다.
3.4버전 부터는 readPreference 옵션을 설정할 때 maxStalenessSeconds 옵셜을 설정하여 MongoDB 드라이버나 Mongos 라우터가 지정된 시간보다 복제 지연이 심한 경우 해당 세컨더리 멤버를 접속 가능한 대상 목록에서 제거하고 접속하지 못하도록 차단합니다.
레플리카 셋의 태그(tag) 기능을 이용해 레플리카 셋의 지역을 나눠 여러 지역에서의 고가용성을 확보할 수도 있습니다. 태그와 nearest 옵션을 사용해 readPreference를 통한 실제 거리상으로 가까운 지역의 레플리카 멤버를 선택하여 쿼리를 할 수도 있습니다.
참고 자료
도서: Real MongoDB
MongoDB Manual: https://docs.mongodb.com/manual/
와우 님 짱이신듯이요
이러한 경우 업데이트를 실행했던 세션은 WriteConflictException을 받고 같은 업데이트 명령을 재시도합니다. 이러한 과정은 MongoDB 서버 프로세스 내부에서만 실행되며, 애플리케이션 단에서는 이런 재시도가 있었는지 알 수 없습니다.
이부분이 조금 애매한것 같은데요. writeConflictException이 발생하면 mongodb내부에서 retry 가 발생하나요??? 저는 application 단으로 전파 되는것 같던데요.